写在前面
最近需要实现一个 AI 语音聊天功能。对比了一圈当前常见的语音 Agent 方案之后,我决定深入阅读 Pipecat 的源码,这篇笔记就是整个阅读过程的整理稿。
可以了解Pipecat 如何组织实时语音 pipeline、如何把 turn detection 与上下文提交衔接起来,以及 function calling / interruption / termination 这些“运行时状态变化”如何被统一收束到 frame 流里。
Pipecat 官网:pipecat.ai
Pipecat 仓库:pipecat-ai/pipecat
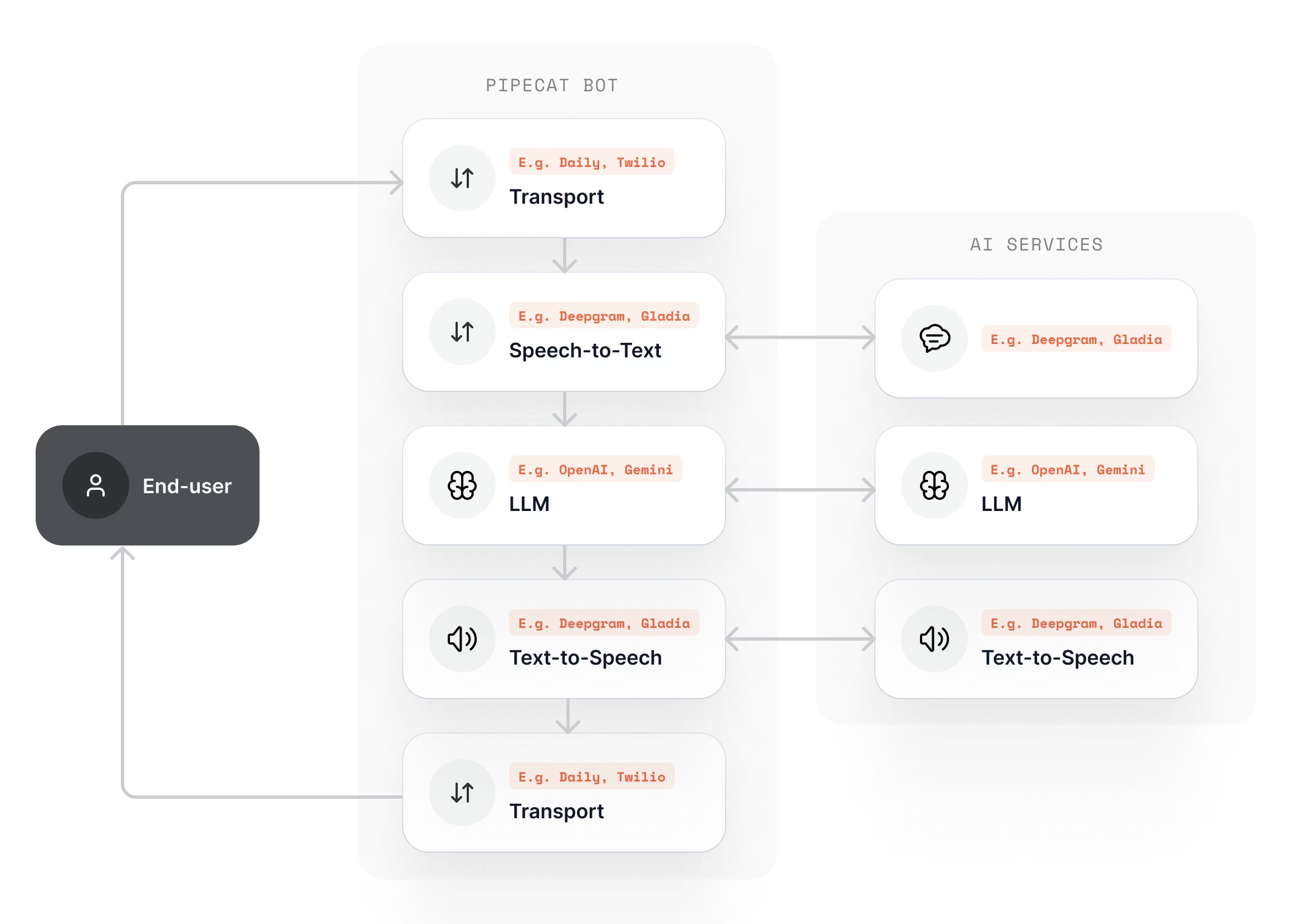
一、Pipeline Architecture:数据如何在 Pipecat 中流动
1.1 Frame: The Universal Data Unit
Source: src/pipecat/frames/frames.py
Pipecat 中的一切都是 Frame。Frame 是一个简单的 @dataclass,包含一个自动生成的 id、一个可读的 name,以及可选的 metadata。
# frames.py:116-154
@dataclass
class Frame:
id: int = field(init=False) # globally unique
name: str = field(init=False) # e.g. "TextFrame#42"
pts: Optional[int] = field(init=False) # presentation timestamp (nanoseconds)
metadata: Dict[str, Any] = field(init=False)
Frames are organized into a three-tier priority hierarchy:
| Base Class | Priority | Interruptible? | Examples |
|---|---|---|---|
SystemFrame | HIGH — always processed first | No | StartFrame, CancelFrame, InterruptionFrame |
DataFrame | Normal — queued in order | Yes — cleared on interruption | AudioRawFrame, TextFrame, ImageRawFrame |
ControlFrame | Normal — queued in order | Yes — cleared on interruption | EndFrame, StopFrame |
设计原则:Frame 的继承层级直接编码了调度策略。 不同于使用标志位或配置项,Frame 的类型本身直接决定了它如何排队、以及是否在中断时被保留。这是经典的类型驱动设计 (Type-Driven Design) —— 类型系统承载了运行时会自动强制执行的语义意义。
UninterruptibleFrame 混入类 (mixin) 用于标记那些即使是 DataFrame 或 ControlFrame 也必须在中断中存活下来的帧:
# frames.py:198-207
@dataclass
class UninterruptibleFrame:
"""A marker for data or control frames that must not be interrupted."""
pass
1.2 FrameProcessor: The Processing Unit
Source: src/pipecat/processors/frame_processor.py
管道中的每个处理器都继承自 FrameProcessor。这是核心的抽象 —— 它定义了帧如何进入、如何被处理、以及如何离开。
The Dual-Queue Architecture
每个 FrameProcessor 拥有两个内部队列,由两个独立的异步任务管理:
┌──────────────────────────────────────────────┐
│ FrameProcessor │
│ │
frame arrives → │ __input_queue (PriorityQueue) │
via queue_frame() │ │ │
│ ├─ SystemFrame? → process immediately │
│ │ (in input task) │
│ └─ Other frame? → put in __process_queue │
│ │
│ __process_queue (asyncio.Queue) │
│ └─ process in FIFO order │
│ (in process task) │
└──────────────────────────────────────────────┘
Key code — the priority queue (frame_processor.py:85-133):
class FrameProcessorQueue(asyncio.PriorityQueue):
HIGH_PRIORITY = 1
LOW_PRIORITY = 2
async def put(self, item):
frame, _, _ = item
if isinstance(frame, SystemFrame):
await super().put((self.HIGH_PRIORITY, self.__high_counter, item))
else:
await super().put((self.LOW_PRIORITY, self.__low_counter, item))
设计原则:通过队列分离来防止优先级反转。
SystemFrames(比如 InterruptionFrame)不会被阻塞在长长的音频帧队列后面。PriorityQueue 保证了它们能被优先取出,而处理任务的分离(__input_frame_task_handler 和 __process_frame_task_handler)则意味着系统帧在一个完全独立的执行路径上被处理。
Key code — the input task (frame_processor.py:1036-1062):
async def __input_frame_task_handler(self):
while True:
(frame, direction, callback) = await self.__input_queue.get()
if isinstance(frame, SystemFrame):
await self.__process_frame(frame, direction, callback) # immediate
else:
await self.__process_queue.put((frame, direction, callback)) # deferred
Direct Mode
Pipeline 容器类(Pipeline, PipelineSource, PipelineSink)会设置 enable_direct_mode=True,这会完全绕过这两个内部队列:
# frame_processor.py:612-632
async def queue_frame(self, frame, direction, callback=None):
if self._enable_direct_mode:
await self.__process_frame(frame, direction, callback) # no queue
else:
await self.__input_queue.put((frame, direction, callback))
设计原则:避免不必要的间接开销。
Pipeline 容器纯粹是路由节点 —— 它们不转换数据,只负责转发帧。为每一个通过 Pipeline 包装器的帧增加队列进出的开销是很浪费的。Direct mode(直通模式)消除了这种开销。
Linking: The Doubly-Linked List
处理器之间通过 _prev 和 _next 指针形成了一个双向链表:
# frame_processor.py:581-589
def link(self, processor: "FrameProcessor"):
self._next = processor
processor._prev = self
推送帧 (Pushing frames) 会根据方向路由到相邻的处理器:
# frame_processor.py:909-944
async def __internal_push_frame(self, frame, direction):
if direction == FrameDirection.DOWNSTREAM and self._next:
await self._next.queue_frame(frame, direction)
elif direction == FrameDirection.UPSTREAM and self._prev:
await self._prev.queue_frame(frame, direction)
设计原则:双向数据流实现了错误传递的解耦。
错误(ErrorFrame)可以向上游流动,而不需要处理器了解任何关于管道拓扑的信息。每个处理器只需简单地把帧向上一级推送,帧自然就会到达任务的源处理器(source handler)。
1.3 Pipeline: The Chain
Source: src/pipecat/pipeline/pipeline.py
Pipeline 将各个处理器按顺序连接起来,并在两端分别包装上 PipelineSource 和 PipelineSink:
# pipeline.py:99-121
class Pipeline(BasePipeline):
def __init__(self, processors, source=None, sink=None):
self._source = source or PipelineSource(self.push_frame)
self._sink = sink or PipelineSink(self.push_frame)
self._processors = [self._source] + processors + [self._sink]
self._link_processors()
def _link_processors(self):
prev = self._processors[0]
for curr in self._processors[1:]:
prev.link(curr)
prev = curr
结果形成如下的链表结构:
Source ←→ Processor1 ←→ Processor2 ←→ ... ←→ ProcessorN ←→ Sink
Nested Pipeline Support
由于 Pipeline 本身也是一个 FrameProcessor,因此管道可以相互嵌套。当一个帧到达嵌套管道时,会被路由到子管道的 source 节点中:
# pipeline.py:183-195
async def process_frame(self, frame, direction):
if direction == FrameDirection.DOWNSTREAM:
await self._source.queue_frame(frame, FrameDirection.DOWNSTREAM)
elif direction == FrameDirection.UPSTREAM:
await self._sink.queue_frame(frame, FrameDirection.UPSTREAM)
PipelineSource 和 PipelineSink 负责处理跨越边界的情况 —— 从子管道流出的帧会被通过回调(self.push_frame)转发给父管道:
# pipeline.py:21-52 (PipelineSource)
async def process_frame(self, frame, direction):
match direction:
case FrameDirection.UPSTREAM:
await self._upstream_push_frame(frame, direction) # escape to parent
case FrameDirection.DOWNSTREAM:
await self.push_frame(frame, direction) # continue in sub-pipeline
设计原则:通过组合模式 (Composite Pattern) 实现统一接口。
Pipeline 本身也就是一个 FrameProcessor。这意味着任何可以接收处理器的地方,同样可以接收一个管道。你可以随意嵌套:Pipeline([Pipeline([A, B]), C, Pipeline([D, E])])。这种双向链表结构对内部的处理器是完全透明的。
1.4 Interruption Handling
当 InterruptionFrame (一种 SystemFrame) 到达处理器时:
# frame_processor.py:892-907
async def _start_interruption(self):
if isinstance(self.__process_current_frame, UninterruptibleFrame):
self.__reset_process_queue() # drain queue, keep current frame
else:
await self.__cancel_process_task() # cancel current processing
self.__create_process_task() # start fresh
重置队列时会保留 UninterruptibleFrame 的实例:
# frame_processor.py:995-1012
def __reset_process_queue(self):
new_queue = asyncio.Queue()
while not self.__process_queue.empty():
item = self.__process_queue.get_nowait()
if isinstance(item[0], UninterruptibleFrame):
new_queue.put_nowait(item)
# swap queues...
设计原则:中断是取消并重启,而不是检查标志位。
框架不是在处理逻辑中到处穿插对"是否已取消"标志位的检查,而是直接取消整个异步任务并创建一个全新的任务。这在无需各个处理器配合检查的情况下,保证了状态的干净。UninterruptibleFrame 为那些无论如何都必须执行完的帧提供了一个逃生通道。
二、PipelineTask:任务编排器
Source: src/pipecat/pipeline/task.py
PipelineTask 会将用户的管道包装在另一个内部带有可控 Source 和 Sink 的独立 Pipeline 中:
# task.py:391-397
source = PipelineSource(self._source_push_frame)
self._sink = PipelineSink(self._sink_push_frame)
processors = [pipeline] # user's pipeline
self._pipeline = Pipeline(processors, source=source, sink=self._sink)
完整的调用链:
Task::Source → [UserPipeline::Source → P1 → P2 → ... → UserPipeline::Sink] → Task::Sink
↑ │
└──────────── upstream frames (errors, task control) ──────────────────────┘
2.1 The Startup Sequence
# task.py:823-864
async def _process_push_queue(self):
self._clock.start()
# Step 1: Create and push StartFrame through the entire pipeline
start_frame = StartFrame(
allow_interruptions=...,
audio_in_sample_rate=...,
enable_metrics=...,
...
)
await self._pipeline.queue_frame(start_frame)
# Step 2: Wait for StartFrame to traverse all processors
await self._wait_for_pipeline_start(start_frame)
# Step 3: Main loop — pull user-queued frames and feed them
while running:
frame = await self._push_queue.get()
await self._pipeline.queue_frame(frame)
if isinstance(frame, (CancelFrame, EndFrame, StopFrame)):
await self._wait_for_pipeline_end(frame)
running = not isinstance(frame, (CancelFrame, EndFrame, StopFrame))
设计原则:StartFrame 作为初始化广播。
与其设计一套单独的初始化协议,不如让 StartFrame 携带所有的配置信息(采样率、指标开关、中断策略等),并通过常规的帧机制流经每一个处理器。每个处理器在它的 process_frame() 方法中,从 StartFrame 里按需读取配置。这确保了所有处理器按顺序完成初始化,并且在任何数据开始流动前,管道已完全就绪。
2.2 Boundary Handlers
任务 Source 端 (Task Source) (task.py:866-903) — 捕获从管道内向上游流出的帧:
async def _source_push_frame(self, frame, direction):
if isinstance(frame, EndTaskFrame):
await self.queue_frame(EndFrame()) # graceful stop
elif isinstance(frame, CancelTaskFrame):
await self.queue_frame(CancelFrame()) # immediate cancel
elif isinstance(frame, ErrorFrame):
if frame.fatal:
await self.queue_frame(CancelFrame()) # fatal → cancel everything
任务 Sink 端 (Task Sink) (task.py:905-936) — 捕获从管道内向下游流出的帧:
async def _sink_push_frame(self, frame, direction):
if isinstance(frame, StartFrame):
self._pipeline_start_event.set() # signal: pipeline is ready
elif isinstance(frame, EndFrame):
self._pipeline_end_event.set() # signal: pipeline is done
elif isinstance(frame, HeartbeatFrame):
await self._heartbeat_queue.put(frame)
设计原则:任务级别的帧 (EndTaskFrame, CancelTaskFrame) 在边界处被转换为管道级别的帧 (EndFrame, CancelFrame)。
这种关注点分离,使得处于管道内部的处理器能够发出"请停止"的信号,而不需要了解外层的 Task 是如何管理生命周期的。Task 层充当了"意图"和"机制"之间的翻译器。
2.3 Lifecycle Events
PipelineTask 提供了一套丰富的事件系统:
@task.event_handler("on_pipeline_started")
async def on_pipeline_started(task, frame):
# Pipeline is ready, StartFrame has traversed all processors
...
@task.event_handler("on_pipeline_finished")
async def on_pipeline_finished(task, frame):
# Pipeline has terminated (EndFrame, StopFrame, or CancelFrame)
...
@task.event_handler("on_pipeline_error")
async def on_pipeline_error(task, frame):
# An ErrorFrame reached the source
...
@task.event_handler("on_idle_timeout")
async def on_idle_timeout(task):
# No activity for idle_timeout_secs
...
2.4 PipelineRunner: The Entry Point
Source: src/pipecat/pipeline/runner.py
最简单的一层封装 — 它只是用信号处理将其包裹在 task.run() 之外:
# runner.py:65-95
class PipelineRunner:
async def run(self, task: PipelineTask):
try:
params = PipelineTaskParams(loop=self._loop)
await task.run(params)
except asyncio.CancelledError:
pass
它配置了 SIGINT/SIGTERM 信号处理器,通过调用 task.cancel() 实现优雅停机。
三、Development Runner:开发期启动基础设施
Source: src/pipecat/runner/run.py
在开发阶段使用的 runner (pipecat.runner.run) 是与管道 runner 完全独立的基础设施。它提供了 bot 接受连接所需的 HTTP/WebSocket/WebRTC 环境。
3.1 Architecture Overview
┌─────────────────────────────────────┐
main() ────────→ │ FastAPI Server (uvicorn) │
│ │
CLI args: │ Transport-specific routes: │
-t webrtc │ /api/offer (WebRTC SDP) │
-t daily │ /start (Daily room) │
-t twilio │ /ws (WebSocket) │
│ / (redirect/status) │
│ │
│ On connection: │
│ 1. Create RunnerArguments │
│ 2. Call bot_module.bot(args) │
└─────────────────────────────────────┘
3.2 Bot Discovery
Runner 启动时会自动去发现用户的 bot() 函数:
# run.py:114-153
def _get_bot_module():
# 1. Check __main__ module (the file that was executed)
main_module = sys.modules["__main__"]
if hasattr(main_module, "bot"):
return main_module
# 2. Try importing 'bot' module from current directory
# 3. Scan .py files in current directory for a 'bot' function
设计原则:约定优于配置 (Convention over configuration)。
Runner 使用了一个简单的约定 —— 你的 bot 文件必须导出一个 async def bot(runner_args) 函数。没有注册表,没有装饰器,也没有配置文件。这和 pytest 测试发现 (test discovery) 遵循的是相同的原则。
3.3 Transport-Specific Argument Types
Source: src/pipecat/runner/types.py
@dataclass
class RunnerArguments: # Base: body, cli_args
class DailyRunnerArguments(RunnerArguments): # + room_url, token
class WebSocketRunnerArguments(RunnerArguments): # + websocket
class SmallWebRTCRunnerArguments(RunnerArguments): # + webrtc_connection
bot 函数利用 isinstance() 检测实际配置在使用的是哪种 transport:
async def bot(runner_args: RunnerArguments):
if isinstance(runner_args, DailyRunnerArguments):
transport = DailyTransport(runner_args.room_url, runner_args.token, ...)
elif isinstance(runner_args, SmallWebRTCRunnerArguments):
transport = SmallWebRTCTransport(runner_args.webrtc_connection, ...)
设计原则:通过类型层级实现多态,而不是强依赖字符串类型的配置字典。
每种 Transport 都有它自己的参数类型,包含了它所需要的特定字段。bot 函数只需使用类型安全的 isinstance() 检查,而不必去解析一个带有各种底层传输特定 key 的字典。
3.4 The proxy_request Endpoint
Source: run.py:302-340
该端点模拟了 Pipecat Cloud 的会话代理,为所有的 WebRTC 客户端提供统一的 API 接口:
@app.api_route(
"/sessions/{session_id}/{path:path}",
methods=["GET", "POST", "PUT", "PATCH", "DELETE"],
)
async def proxy_request(session_id, path, request, background_tasks):
# 1. Validate session exists
active_session = active_sessions.get(session_id)
if active_session is None:
return Response(content="Invalid or not-yet-ready session_id", status_code=404)
# 2. Route WebRTC signaling to the offer/ice handlers
if path.endswith("api/offer"):
if request.method == "POST":
# Parse SDP offer, delegate to offer() handler
webrtc_request = SmallWebRTCRequest(sdp=..., type=..., ...)
return await offer(webrtc_request, background_tasks)
elif request.method == "PATCH":
# Parse ICE candidate, delegate to ice_candidate() handler
return await ice_candidate(patch_request)
# 3. Other paths: just acknowledge
return Response(status_code=200)
数据流程:/start 创建 session → 客户端向 /sessions/{id}/api/offer 发起 WebRTC 信令 → proxy_request 进行转化并委派给真正的 WebRTC handler处理。
设计原则:本地开发环境直接镜像生产环境的 API。
通过模拟 Pipecat Cloud 的 /start 和 /sessions/{id}/... 接口层,在本地开发的 bot 可以零修改地直接部署到生产环境并获得一致的表现。代理模式在这里充当了云端 API 和本地 WebRTC 处理程序之间的适配器。
了解了解
3.5 Session Lifecycle
Client Server
│ │
│ POST /start │
│ { enableDefaultIceServers } │
│ ─────────────────────────────→ │ Creates session_id, stores in active_sessions
│ ←───────────────────────────── │ { sessionId, iceConfig }
│ │
│ POST /sessions/{id}/api/offer │
│ { sdp, type } │
│ ─────────────────────────────→ │ proxy_request → offer()
│ │ → SmallWebRTCRequestHandler
│ │ → Creates SmallWebRTCConnection
│ │ → Spawns bot(runner_args) in background
│ ←───────────────────────────── │ { sdp answer }
│ │
│ PATCH /sessions/{id}/api/offer│
│ { candidates } │
│ ─────────────────────────────→ │ proxy_request → ice_candidate()
│ ←───────────────────────────── │ { status: success }
│ │
│ ══════ WebRTC media flow ═════│ Bot pipeline running...
四、Observer System:AOP 风格的横切观察
Pipecat 的 Observer 系统用观察者模式实现了类似 Spring AOP 的切面拦截能力,将性能打点、延迟测量、会话追踪等横切关注点与业务逻辑彻底解耦。
4.1 两个固定拦截点 — 类比 AOP 的 @Before 和 @AfterReturning
所有 Observer 的数据来源只有 FrameProcessor 基类中的两个拦截点,硬编码在每个 Frame 的生命周期里:
拦截点 1: process_frame() 入口 — “帧到达处理器”
# frame_processor.py:660-675
async def process_frame(self, frame: Frame, direction: FrameDirection):
if self._observer:
timestamp = self._clock.get_time() if self._clock else 0
data = FrameProcessed(
processor=self, # 谁在处理
frame=frame, # 处理什么帧
direction=direction, # 哪个方向
timestamp=timestamp, # 精确时间戳
)
await self._observer.on_process_frame(data)
# ... 然后才执行真正的处理逻辑
这相当于 Spring AOP 的 @Before — 在业务逻辑执行之前通知 Observer。
拦截点 2: __internal_push_frame() 出口 — “帧离开处理器”
# frame_processor.py:910-942
async def __internal_push_frame(self, frame, direction):
timestamp = self._clock.get_time() if self._clock else 0
if direction == FrameDirection.DOWNSTREAM and self._next:
if self._observer:
data = FramePushed(
source=self, # 谁推送的
destination=self._next, # 推给谁
frame=frame,
direction=direction,
timestamp=timestamp,
)
await self._observer.on_push_frame(data)
await self._next.queue_frame(frame, direction)
elif direction == FrameDirection.UPSTREAM and self._prev:
if self._observer:
data = FramePushed(
source=self,
destination=self._prev,
frame=frame,
direction=direction,
timestamp=timestamp,
)
await self._observer.on_push_frame(data)
await self._prev.queue_frame(frame, direction)
这相当于 @AfterReturning — 在处理器完成处理并推送帧时通知 Observer。
为什么只需要两个拦截点? 通过时间差计算就能得到任何处理器的处理耗时:
处理器耗时 = on_push_frame(timestamp) - on_process_frame(timestamp)
这是 StartupTimingObserver 测量每个处理器 start() 耗时的核心原理。
4.2 Observer 接口 — 极简的三方法协议
# base_observer.py
class BaseObserver(BaseObject):
async def on_process_frame(self, data: FrameProcessed):
"""帧到达处理器时调用"""
pass
async def on_push_frame(self, data: FramePushed):
"""帧从处理器推出时调用"""
pass
async def on_pipeline_started(self):
"""StartFrame 遍历完所有处理器后调用"""
pass
两个数据载体:
| 数据类 | 字段 | 含义 |
|---|---|---|
FrameProcessed | processor, frame, direction, timestamp | 谁在处理什么帧 |
FramePushed | source, destination, frame, direction, timestamp | 帧从谁流向谁 |
Observer 只能看,不能改 — 没有返回值,没有取消机制。这保证了 Observer 永远不会影响管道行为。
4.3 TaskObserver 代理 — 异步队列隔离
如果 Observer 直接在 process_frame() / __internal_push_frame() 中执行,一个慢的 Observer 会阻塞整个管道。Pipecat 用 TaskObserver 代理模式解决了这个问题:
┌─────────────────────────────────────┐
│ TaskObserver (代理) │
FrameProcessor ───→│ │
on_push_frame() │ ┌──Queue──→ Task ──→ Observer A │
│ ├──Queue──→ Task ──→ Observer B │
│ └──Queue──→ Task ──→ Observer C │
└─────────────────────────────────────┘
关键实现:
# task_observer.py
class TaskObserver(BaseObserver):
def _create_proxy(self, observer):
queue = asyncio.Queue() # 每个 Observer 独立队列
task = self._task_manager.create_task(
self._proxy_task_handler(queue, observer), # 独立消费协程
f"TaskObserver::{observer}::_proxy_task_handler",
)
return Proxy(queue=queue, task=task, observer=observer)
async def _send_to_proxy(self, data):
for proxy in self._proxies.values():
await proxy.queue.put(data) # 非阻塞地分发到所有队列
async def _proxy_task_handler(self, queue, observer):
while True:
data = await queue.get()
if isinstance(data, _PipelineStartedSignal):
await observer.on_pipeline_started()
elif isinstance(data, FramePushed):
await observer.on_push_frame(data)
elif isinstance(data, FrameProcessed):
await observer.on_process_frame(data)
queue.task_done()
这带来三个关键好处:
- 管道零阻塞:
_send_to_proxy()只做queue.put(),几乎零耗时 - Observer 间互相隔离:Observer A 卡住不影响 Observer B
- 动态增删:运行时可以
add_observer()/remove_observer()
4.4 Observer 注册流程 — 从用户代码到每个处理器
用户代码 PipelineTask FrameProcessor
│ │ │
│ PipelineTask(pipeline, │ │
│ observers=[obs_a, obs_b]) │ │
│ ─────────────────────────→ │ │
│ │ 1. 创建 TaskObserver( │
│ │ observers=[obs_a,obs_b])│
│ │ │
│ │ 2. FrameProcessorSetup( │
│ │ observer=task_observer) │
│ │ ──────────────────────────→ │
│ │ │ 3. self._observer = setup.observer
│ │ │ (所有处理器共享同一个 TaskObserver)
│ │ │
│ │ 4. task_observer.start() │
│ │ → 为每个 observer 创建 │
│ │ 独立的 Queue + Task │
# task.py:799-804 — Observer 注入到管道的每个处理器
setup = FrameProcessorSetup(
clock=self._clock,
task_manager=self._task_manager,
observer=self._observer, # TaskObserver 实例
)
await self._pipeline.setup(setup) # 递归传播到所有处理器
# task.py:402 — TaskObserver 创建
self._observer = TaskObserver(observers=observers, task_manager=self._task_manager)
4.5 三个内置 Observer 实例详解
4.5.1 StartupTimingObserver — 启动耗时度量
源码: src/pipecat/observers/startup_timing_observer.py
解决的问题: 管道里有十几个处理器(STT、LLM、TTS、Transport),哪个的 start() 最慢?如果不测量,启动慢了只能盲猜。
核心思路:利用 AOP 两个拦截点的时间差
StartFrame 会从管道头部流到尾部,每经过一个处理器都会触发 process_frame()(进入)和 push_frame()(离开)。两个时间戳之差就是该处理器 start() 的精确耗时。
状态与数据结构
# startup_timing_observer.py:53-59
@dataclass
class _ArrivalInfo:
"""内部记录:StartFrame 到达某处理器的时间"""
processor: FrameProcessor
arrival_ts_ns: int # 纳秒级时间戳
# 核心状态
self._arrivals: Dict[int, _ArrivalInfo] = {} # processor.id → 到达信息
self._timings: List[ProcessorStartupTiming] = [] # 按管道顺序收集的耗时
self._start_frame_id: Optional[str] = None # 锁定第一个 StartFrame(防重复)
self._start_frame_arrival_ns: Optional[int] = None # 全局起始时间(算 offset 用)
拦截点 1: on_process_frame — 记录"到达"
# startup_timing_observer.py:224-247
async def on_process_frame(self, data: FrameProcessed):
if self._startup_timing_reported:
return # 报告已发,不再追踪
if not isinstance(data.frame, StartFrame):
return # 只关心 StartFrame
# 锁定第一个 StartFrame(ParallelPipeline 中可能有多个 StartFrame 副本)
if self._start_frame_id is None:
self._start_frame_id = data.frame.id
self._start_frame_arrival_ns = data.timestamp # 全局起点
self._start_wall_clock = time.time()
elif data.frame.id != self._start_frame_id:
return # 忽略其他 StartFrame
if self._should_track(data.processor):
self._arrivals[data.processor.id] = _ArrivalInfo(
processor=data.processor,
arrival_ts_ns=data.timestamp, # 记录到达时间
)
关键设计:_start_frame_id 锁定机制。 ParallelPipeline 会复制 StartFrame 发给每条并行分支。如果不锁定 frame ID,不同分支的 StartFrame 副本会互相干扰。
_should_track() 过滤器:
# startup_timing_observer.py:200-212
_INTERNAL_TYPES = (PipelineSource, BasePipeline) # 内部管道组件
def _should_track(self, processor):
if self._processor_types is not None:
return isinstance(processor, self._processor_types) # 用户指定类型
return not isinstance(processor, _INTERNAL_TYPES) # 默认排除内部组件
默认过滤掉 PipelineSource、BasePipeline 等纯路由节点,因为它们的 start() 几乎为零,加入报告只会增加噪音。
拦截点 2: on_push_frame — 计算"耗时"
# startup_timing_observer.py:249-289
async def on_push_frame(self, data: FramePushed):
# ---- 传输层建连度量(与启动度量独立)----
if isinstance(data.frame, BotConnectedFrame):
self._handle_bot_connected(data)
return
if isinstance(data.frame, ClientConnectedFrame):
await self._handle_client_connected(data)
return
# ---- StartFrame 度量 ----
if self._startup_timing_reported:
return
if not isinstance(data.frame, StartFrame):
return
if self._start_frame_id is not None and data.frame.id != self._start_frame_id:
return
arrival = self._arrivals.pop(data.source.id, None) # 取出到达记录
if arrival is None:
return
duration_ns = data.timestamp - arrival.arrival_ts_ns # 核心公式:推出时间 - 到达时间
duration_secs = duration_ns / 1e9
# offset = 该处理器开始的时间点 - 全局起始时间
start_offset_secs = (arrival.arrival_ts_ns - self._start_frame_arrival_ns) / 1e9
self._timings.append(
ProcessorStartupTiming(
processor_name=arrival.processor.name,
start_offset_secs=start_offset_secs, # 可以画 Gantt 图
duration_secs=duration_secs,
)
)
每个 ProcessorStartupTiming 记录了两个维度:
start_offset_secs: 相对于管道启动的偏移(用于时间线/甘特图)duration_secs: 自身start()耗时
报告触发:on_pipeline_started
# startup_timing_observer.py:214-222
async def on_pipeline_started(self):
"""StartFrame 遍历完所有处理器后由 PipelineTask 调用"""
if self._timings:
await self._emit_report()
async def _emit_report(self):
self._startup_timing_reported = True # 防重复
total = sum(t.duration_secs for t in self._timings)
report = StartupTimingReport(
start_time=self._start_wall_clock or 0.0,
total_duration_secs=total,
processor_timings=self._timings,
)
await self._call_event_handler("on_startup_timing_report", report)
为什么不在最后一个 on_push_frame 时发报告? 因为 ParallelPipeline 中多条分支并行处理 StartFrame,Observer 无法知道哪个是"最后一个"。所以用 on_pipeline_started() 这个专门的回调 — 它由 PipelineTask 在确认 StartFrame 遍历完所有分支后才调用。
传输层建连度量(附加功能)
# startup_timing_observer.py:291-312
def _handle_bot_connected(self, data: FramePushed):
"""第一个 BotConnectedFrame → bot 加入房间的延迟"""
if self._bot_connected_secs is not None:
return # 只记第一次
delta_ns = data.timestamp - self._start_frame_arrival_ns
self._bot_connected_secs = delta_ns / 1e9
async def _handle_client_connected(self, data: FramePushed):
"""第一个 ClientConnectedFrame → 客户端连入的延迟,并触发传输报告"""
if self._transport_timing_reported:
return
self._transport_timing_reported = True
delta_ns = data.timestamp - self._start_frame_arrival_ns
report = TransportTimingReport(
start_time=self._start_wall_clock or 0.0,
bot_connected_secs=self._bot_connected_secs, # SFU 传输才有
client_connected_secs=delta_ns / 1e9,
)
await self._call_event_handler("on_transport_timing_report", report)
这巧妙地复用了同一个 Observer 的 on_push_frame 拦截点来追踪额外的帧类型。一个 Observer 可以同时关注多种帧。
完整数据流时序
时间 ──────────────────────────────────────────────────────────────────→
StartFrame 到达 STT StartFrame 离开 STT StartFrame 到达 LLM StartFrame 离开 LLM
│ │ │ │
▼ ▼ ▼ ▼
on_process_frame on_push_frame on_process_frame on_push_frame
记录 arrival[stt] duration = t2 - t1 记录 arrival[llm] duration = t4 - t3
t1 t2 t3 t4
...所有处理器遍历完毕...
on_pipeline_started()
│
▼
emit StartupTimingReport
[STT: 0.12s, LLM: 0.05s, TTS: 0.08s]
4.5.2 TurnTrackingObserver — 会话轮次状态机
源码: src/pipecat/observers/turn_tracking_observer.py
解决的问题: 在语音对话中,如何知道"一轮对话"从哪里开始、到哪里结束?用户打断了怎么算?Bot 说话中间停顿了怎么算?
核心思路:纯粹通过观察帧流来维护状态机
这个 Observer 只用 on_push_frame,不需要 on_process_frame。它不关心帧在哪个处理器被处理,只关心帧的类型和顺序。
状态变量
# turn_tracking_observer.py:46-67
def __init__(self, max_frames=100, turn_end_timeout_secs=2.5, **kwargs):
self._turn_count = 0 # 总轮次计数
self._is_turn_active = False # 当前是否有活跃轮次
self._is_bot_speaking = False # Bot 正在说话?
self._has_bot_spoken = False # 当前轮次中 Bot 是否说过话?
self._turn_start_time = 0 # 当前轮次开始时间(纳秒)
self._turn_end_timeout_secs = turn_end_timeout_secs # 默认 2.5 秒
# 帧去重机制(同一帧可能被多个处理器推送,只处理一次)
self._processed_frames = set()
self._frame_history = deque(maxlen=max_frames) # 有界,防内存泄漏
帧去重机制 — 为什么需要它?
一个帧从 ProcessorA 推送到 ProcessorB 时,on_push_frame 会触发。但同一个帧可能经过多个处理器(A→B→C),每次推送都会触发一次 on_push_frame。状态机只应该对每个帧反应一次。
# turn_tracking_observer.py:78-89
async def on_push_frame(self, data: FramePushed):
if data.frame.id in self._processed_frames:
return # 已处理过,跳过
self._processed_frames.add(data.frame.id)
self._frame_history.append(data.frame.id)
# 有界 deque 满了后会自动丢弃最老的,但 set 不会
# 所以需要定期从 deque 重建 set,防止 set 无限增长
if len(self._processed_frames) > len(self._frame_history):
self._processed_frames = set(self._frame_history)
设计亮点:deque(maxlen=N) + set 组合实现了有界去重。deque 负责自动淘汰最老的 N 个帧 ID,set 负责 O(1) 查重。当 set 比 deque 大时(说明 deque 已自动丢弃了老数据),用 deque 内容重建 set。
状态机完整转换表
# turn_tracking_observer.py:91-104 — 主分发逻辑
if isinstance(data.frame, StartFrame):
if self._turn_count == 0:
await self._start_turn(data) # 管道启动 → 第一轮开始
elif isinstance(data.frame, UserStartedSpeakingFrame):
await self._handle_user_started_speaking(data)
elif isinstance(data.frame, BotStartedSpeakingFrame):
await self._handle_bot_started_speaking(data)
elif isinstance(data.frame, BotStoppedSpeakingFrame) and self._is_bot_speaking:
await self._handle_bot_stopped_speaking(data)
elif isinstance(data.frame, (EndFrame, CancelFrame)):
await self._handle_pipeline_end(data)
| 当前状态 | 触发帧 | 动作 | 新状态 |
|---|---|---|---|
| 无轮次 (count=0) | StartFrame | _start_turn() → 轮次 1 开始 | 轮次活跃 |
| 轮次活跃, Bot 在说话 | UserStartedSpeaking | 结束当前轮(interrupted=True) → 开始新轮 | 新轮次活跃 |
| 轮次活跃, Bot 已说过话, 超时中 | UserStartedSpeaking | 取消超时 → 结束当前轮 → 开始新轮 | 新轮次活跃 |
| 轮次不活跃 | UserStartedSpeaking | _start_turn() | 轮次活跃 |
| 轮次活跃, 用户说话中 | UserStartedSpeaking | 忽略(用户还在同一轮里说话) | 不变 |
| 任意 | BotStartedSpeaking | 标记 bot_speaking=True, 取消超时 | 不变 |
| Bot 在说话 | BotStoppedSpeaking | 标记 bot_speaking=False, 启动超时计时器 | 等待超时 |
| 等待超时, 2.5s 到期 | (timeout) | _end_turn(interrupted=False) | 轮次不活跃 |
| 轮次活跃 | EndFrame/CancelFrame | 强制结束当前轮 | 轮次不活跃 |
打断处理 — 最复杂的分支
# turn_tracking_observer.py:131-149
async def _handle_user_started_speaking(self, data: FramePushed):
if self._is_bot_speaking:
# 场景 1: Bot 正在说话时用户开口 → 打断
self._cancel_turn_end_timer()
await self._end_turn(data, was_interrupted=True) # 结束旧轮
self._is_bot_speaking = False
await self._start_turn(data) # 开始新轮
elif self._is_turn_active and self._has_bot_spoken:
# 场景 2: Bot 停了但还没超时(2.5s 内用户又说话了)
# 这不算打断,但算新轮次的自然开始
self._cancel_turn_end_timer()
await self._end_turn(data, was_interrupted=False)
await self._start_turn(data)
elif not self._is_turn_active:
# 场景 3: 前一轮已结束,用户重新开口
await self._start_turn(data)
else:
# 场景 4: 用户在 Bot 回复前继续说话(比如补充了一句)
logger.trace(f"User is already speaking in Turn {self._turn_count}")
超时计时器 — 为什么不直接在 BotStoppedSpeaking 时结束轮次?
# turn_tracking_observer.py:106-116
def _schedule_turn_end(self, data: FramePushed):
self._cancel_turn_end_timer()
loop = asyncio.get_event_loop()
self._end_turn_timer = loop.call_later(
self._turn_end_timeout_secs, # 默认 2.5 秒
lambda: asyncio.create_task(self._end_turn_after_timeout(data)),
)
原因:Bot 可能中间短暂停顿。 比如:
- Bot 说 “让我查一下…” →
BotStoppedSpeaking - 调用工具,等待 1 秒
- Bot 继续 “查到了,结果是…” →
BotStartedSpeaking
如果在步骤 1 就结束轮次,会把一次完整的对话拆成两轮。2.5 秒超时允许 Bot 在工具调用、HTTP TTS 服务等场景下短暂停顿而不中断轮次。
当 BotStartedSpeaking 在超时内到达时,计时器被取消:
# turn_tracking_observer.py:151-156
async def _handle_bot_started_speaking(self, data: FramePushed):
self._is_bot_speaking = True
self._has_bot_spoken = True
self._cancel_turn_end_timer() # Bot 又开始说话了,取消超时
事件输出
# turn_tracking_observer.py:174-193
async def _start_turn(self, data: FramePushed):
self._is_turn_active = True
self._has_bot_spoken = False
self._turn_count += 1
self._turn_start_time = data.timestamp
await self._call_event_handler("on_turn_started", self._turn_count)
async def _end_turn(self, data: FramePushed, was_interrupted: bool):
if not self._is_turn_active:
return
duration = (data.timestamp - self._turn_start_time) / 1_000_000_000
self._is_turn_active = False
await self._call_event_handler("on_turn_ended", self._turn_count, duration, was_interrupted)
事件参数:
on_turn_started(observer, turn_count)— 第几轮on_turn_ended(observer, turn_count, duration_secs, was_interrupted)— 第几轮、持续多久、是否被打断
4.5.3 UserBotLatencyObserver — 用户到机器人响应延迟
源码: src/pipecat/observers/user_bot_latency_observer.py
解决的问题: 测量"用户说完话到机器人开口"的端到端延迟(即 TTFS — Time to First Speech),并按服务拆分延迟明细(LLM TTFB、TTS TTFB、文本聚合、工具调用)。
核心思路:追踪一个完整的"用户→Bot"响应周期
用户说话中 用户停止说话 STT+分析完成 LLM 响应 TTS 播放
│ │ │ │ │
▼ ▼ ▼ ▼ ▼
VADUserStarted VADUserStopped UserStoppedSpeaking MetricsFrame BotStartedSpeaking
Speaking Speaking Frame (TTFB/TextAgg) │
│ │ │ │ │
│ │◄─── user_turn ────►│ │ │
│ │◄───────────── total latency ─────────────────────────►│
状态与数据结构
# user_bot_latency_observer.py:172-200
def __init__(self, *, max_frames=100, **kwargs):
# 核心时间戳
self._user_stopped_time: Optional[float] = None # VAD 确认用户停止说话的时间
self._user_turn_start_time: Optional[float] = None # 同上(用于 breakdown)
self._user_turn: Optional[float] = None # user turn 持续时间
# 首次 Bot 说话追踪
self._client_connected_time: Optional[float] = None
self._first_bot_speech_measured: bool = False
# 帧去重(同 TurnTrackingObserver)
self._processed_frames: set = set()
self._frame_history: deque = deque(maxlen=max_frames)
# 每轮周期的指标累加器
self._ttfb: List[TTFBBreakdownMetrics] = []
self._text_aggregation: Optional[TextAggregationBreakdownMetrics] = None
self._function_call_starts: Dict[str, tuple[str, float]] = {}
self._function_call_metrics: List[FunctionCallMetrics] = []
帧处理分发 — 只用 on_push_frame + 只看下游
# user_bot_latency_observer.py:206-280
async def on_push_frame(self, data: FramePushed):
if data.direction != FrameDirection.DOWNSTREAM:
return # 只关心下游帧(数据流方向)
# 帧去重(同 TurnTrackingObserver 的 deque+set 方案)
if data.frame.id in self._processed_frames:
return
self._processed_frames.add(data.frame.id)
self._frame_history.append(data.frame.id)
...
完整的帧处理逻辑
1. 用户开始说话 → 重置一切
if isinstance(data.frame, VADUserStartedSpeakingFrame):
self._user_stopped_time = None
self._user_turn_start_time = None
self._user_turn = None
self._reset_accumulators() # 清空 TTFB、文本聚合、工具调用指标
self._first_bot_speech_measured = True # 放弃首次 Bot 说话测量
用户一开口,之前所有累积的指标都作废(可能是被打断了)。
2. VAD 确认用户停止说话 → 记录起始时间
elif isinstance(data.frame, VADUserStoppedSpeakingFrame):
# 关键:减去 stop_secs(VAD 需要的静默检测时间)
# 这样得到的是用户"真正"停止说话的时间
self._user_stopped_time = data.frame.timestamp - data.frame.stop_secs
self._user_turn_start_time = self._user_stopped_time
为什么要减 stop_secs? VAD 需要检测到 N 秒静默后才确认用户停止说话。如果 VAD 在 t=5.3s 触发,stop_secs=0.3s,那用户实际在 t=5.0s 就停了。延迟应该从 5.0s 算起,否则会系统性地低估 0.3s。
3. UserStoppedSpeaking → 计算 user turn 耗时
elif isinstance(data.frame, UserStoppedSpeakingFrame):
if self._user_stopped_time is not None:
self._user_turn = time.time() - self._user_stopped_time
user_turn = 从用户实际停止说话 → 到轮次被释放。这段时间包括:
- VAD 静默检测(
stop_secs) - STT 最终化(等待最终识别结果)
- Turn Analyzer 分析等待(判断用户是否说完了意思)
4. 打断 → 丢弃脏数据
elif isinstance(data.frame, InterruptionFrame):
self._reset_accumulators() # LLM/TTS 被取消了,之前收集的指标无效
5. 工具调用追踪 → 配对计时
elif isinstance(data.frame, FunctionCallInProgressFrame):
# 工具开始执行 → 记录 tool_call_id 和开始时间
self._function_call_starts[data.frame.tool_call_id] = (
data.frame.function_name,
time.time(),
)
elif isinstance(data.frame, FunctionCallResultFrame):
# 工具返回结果 → 计算耗时
start = self._function_call_starts.pop(data.frame.tool_call_id, None)
if start is not None:
function_name, start_time = start
self._function_call_metrics.append(
FunctionCallMetrics(
function_name=function_name,
start_time=start_time,
duration_secs=time.time() - start_time,
)
)
用 tool_call_id 做配对,支持多个工具并发执行。
6. MetricsFrame → 收集服务级 TTFB
elif isinstance(data.frame, MetricsFrame):
self._handle_metrics_frame(data.frame)
# user_bot_latency_observer.py:310-342
def _handle_metrics_frame(self, frame: MetricsFrame):
# 只在有效测量窗口内收集(用户停了或等首次 Bot 说话)
waiting_for_first_speech = (
self._client_connected_time is not None and not self._first_bot_speech_measured
)
if self._user_stopped_time is None and not waiting_for_first_speech:
return
now = time.time()
for metrics_data in frame.data:
if isinstance(metrics_data, TTFBMetricsData) and metrics_data.value > 0:
self._ttfb.append(
TTFBBreakdownMetrics(
processor=metrics_data.processor, # "DeepgramSTT", "OpenAILLM" 等
model=metrics_data.model, # "gpt-4o", "nova-2" 等
start_time=now - metrics_data.value, # 反算开始时间
duration_secs=metrics_data.value,
)
)
elif isinstance(metrics_data, TextAggregationMetricsData):
if self._text_aggregation is None: # 只取第一个(影响首段语音的那个)
self._text_aggregation = TextAggregationBreakdownMetrics(
processor=metrics_data.processor,
start_time=now - metrics_data.value,
duration_secs=metrics_data.value,
)
为什么只取第一个 TextAggregation? 句子聚合器可能产生多次 MetricsFrame(每聚合一句就报一次),但只有第一次影响"首段语音延迟"。后续的聚合和前一段 TTS 并行执行,不计入延迟瓶颈。
7. BotStartedSpeaking → 计算总延迟 + 发射事件
# user_bot_latency_observer.py:282-308
async def _handle_bot_started_speaking(self):
emit_breakdown = False
# 一次性测量:客户端连入 → 首次 Bot 说话(greeting 延迟)
if self._client_connected_time is not None and not self._first_bot_speech_measured:
self._first_bot_speech_measured = True
latency = time.time() - self._client_connected_time
await self._call_event_handler("on_first_bot_speech_latency", latency)
emit_breakdown = True
# 常规测量:用户停止说话 → Bot 开始说话
if self._user_stopped_time is not None:
latency = time.time() - self._user_stopped_time
self._user_stopped_time = None
await self._call_event_handler("on_latency_measured", latency)
emit_breakdown = True
if emit_breakdown:
breakdown = LatencyBreakdown(
ttfb=list(self._ttfb),
text_aggregation=self._text_aggregation,
user_turn_start_time=self._user_turn_start_time,
user_turn_secs=self._user_turn,
function_calls=list(self._function_call_metrics),
)
await self._call_event_handler("on_latency_breakdown", breakdown)
self._reset_accumulators()
LatencyBreakdown 数据模型 — 按时间排序的事件链
# user_bot_latency_observer.py:114-141
class LatencyBreakdown(BaseModel):
ttfb: List[TTFBBreakdownMetrics] # LLM TTFB, TTS TTFB
text_aggregation: Optional[TextAggregationBreakdownMetrics] # 句子聚合延迟
user_turn_start_time: Optional[float] # 用户停止说话的时间
user_turn_secs: Optional[float] # VAD+STT+分析器延迟
function_calls: List[FunctionCallMetrics] # 工具调用延迟
def chronological_events(self) -> List[str]:
"""按时间排序输出人类可读的事件链"""
events = []
if self.user_turn_start_time and self.user_turn_secs:
events.append((self.user_turn_start_time, f"User turn: {self.user_turn_secs:.3f}s"))
for t in self.ttfb:
events.append((t.start_time, f"{t.processor}: TTFB {t.duration_secs:.3f}s"))
for fc in self.function_calls:
events.append((fc.start_time, f"{fc.function_name}: {fc.duration_secs:.3f}s"))
if self.text_aggregation:
ta = self.text_aggregation
events.append((ta.start_time, f"{ta.processor}: text aggregation {ta.duration_secs:.3f}s"))
events.sort(key=lambda e: e[0])
return [label for _, label in events]
输出示例:
User turn: 0.482s
DeepgramSTT: TTFB 0.123s
OpenAILLM: TTFB 0.341s
get_weather: 0.892s
ElevenLabsTTS: TTFB 0.187s
SentenceAggregator: text aggregation 0.045s
三个事件的语义区分
| 事件 | 触发条件 | 语义 |
|---|---|---|
on_first_bot_speech_latency | 客户端连入后首次 BotStartedSpeaking,只触发一次 | 衡量 greeting 延迟(用户刚进来到 Bot 说第一句话) |
on_latency_measured | 每次用户停止说话后 BotStartedSpeaking | 衡量单轮用户→Bot 响应延迟 |
on_latency_breakdown | 与上两个同时触发 | 提供按服务拆分的延迟明细 |
4.5.4 三个 Observer 的设计模式对比
| 维度 | StartupTiming | TurnTracking | UserBotLatency |
|---|---|---|---|
| 用到的拦截点 | on_process_frame + on_push_frame | 仅 on_push_frame | 仅 on_push_frame |
| 关注的帧类型 | StartFrame, BotConnected, ClientConnected | StartFrame, UserStarted/Stopped, BotStarted/Stopped, End/Cancel | VADUserStarted/Stopped, UserStopped, BotStarted, Interruption, FunctionCall*, Metrics, ClientConnected |
| 状态复杂度 | 低(map + list) | 中(状态机 + 计时器) | 高(多指标累加器 + 配对追踪) |
| 帧去重 | 不需要(只看 StartFrame,用 frame.id 锁定) | 需要(deque+set) | 需要(deque+set) |
| 触发频率 | 一次性(启动时) | 每轮一次 | 每轮一次 |
| 核心技巧 | 两个拦截点的时间差 | 帧序列 → 状态转换 | 帧序列 → 指标收集 → 打包发射 |
4.6 Observer 解决了什么问题?
没有 Observer 时(强耦合方式):
class MySTTService(STTService):
async def process_frame(self, frame, direction):
# ❌ 业务逻辑和打点代码交织在一起
start = time.time()
logger.info(f"Processing {frame}")
metrics.record("stt_process_start", start)
result = await self._recognize(frame) # 真正的业务逻辑
elapsed = time.time() - start
metrics.record("stt_latency", elapsed)
logger.info(f"STT took {elapsed:.3f}s")
await self.push_frame(result)
有 Observer 时(彻底解耦):
# STT 服务只关心业务
class MySTTService(STTService):
async def process_frame(self, frame, direction):
result = await self._recognize(frame)
await self.push_frame(result)
# 性能监控独立为 Observer,零侵入
observer = StartupTimingObserver()
@observer.event_handler("on_startup_timing_report")
async def on_report(observer, report):
for t in report.processor_timings:
print(f"{t.processor_name}: {t.duration_secs:.3f}s")
task = PipelineTask(pipeline, observers=[observer])
| 维度 | 无 Observer | 有 Observer |
|---|---|---|
| 服务代码 | 充斥打点/日志代码 | 纯业务逻辑 |
| 添加新指标 | 修改每个服务 | 新增一个 Observer |
| 移除监控 | 修改每个服务 | 不传 Observer 即可 |
| 监控影响管道 | 可能(慢日志阻塞) | 不可能(队列隔离) |
| 运行时切换 | 困难 | add_observer() / remove_observer() |
4.7 与 Spring AOP 的类比
| Spring AOP 概念 | Pipecat Observer 对应 |
|---|---|
JoinPoint (连接点) | FrameProcessed / FramePushed 数据对象 |
Pointcut (切点) | 固定两个: process_frame() 入口 + __internal_push_frame() 出口 |
Advice (通知) | on_process_frame() = @Before, on_push_frame() = @AfterReturning |
Aspect (切面) | 一个 BaseObserver 子类 = 一个切面 |
Weaving (织入) | FrameProcessorSetup 将 TaskObserver 注入所有处理器 |
Proxy (代理) | TaskObserver 用队列+协程代理所有 Observer |
关键差异: Spring AOP 的切点可以用表达式匹配任意方法,Pipecat 的切点是固定的两个位置。这是刻意的设计简化 — 对于管道架构来说,“帧进入” 和 “帧离开” 两个点就足以覆盖所有监控需求(耗时 = 出 - 入,流量 = 计数推送次数,状态 = 观察帧类型序列)。
五、Speech Input & Turn Detection:语音输入与轮次检测
语音对话的核心挑战是:如何判断用户什么时候开始说话、什么时候说完了?
这不是简单的"检测到声音=开始,没声音=结束"。用户会停顿思考、会被噪音干扰、会在句子中间换气。Pipecat 通过一个多层策略架构来解决这个问题。
5.1 整体架构:三层检测管道
原始音频流 ──→ [VAD 层] ──→ [Turn Start 策略层] ──→ [Turn Stop 策略层] ──→ 管道下游
│ │ │ │
│ ▼ ▼ ▼
│ VADUserStarted UserStartedSpeaking UserStoppedSpeaking
│ VADUserStopped + 中断 + 触发 LLM
│ │ │ │
└──→ [STT 服务] ──→ TranscriptionFrame ──────────────→ ─┘
三层各司其职:
| 层级 | 组件 | 输入 | 输出 | 关注点 |
|---|---|---|---|---|
| 第一层:VAD | VADAnalyzer + VADController | 原始音频 PCM | VADUserStarted/StoppedSpeakingFrame | 物理层面的声音活动检测 |
| 第二层:Turn Start | BaseUserTurnStartStrategy 实现 | VAD帧、转录帧 | UserStartedSpeakingFrame + 中断 | 决定"用户开始了一个新轮次" |
| 第三层:Turn Stop | BaseUserTurnStopStrategy 实现 | VAD帧、转录帧、音频帧 | UserStoppedSpeakingFrame | 决定"用户说完了,可以回应" |
关键区别:VAD 帧是物理层信号(“检测到声音/停止声音”),User 帧是语义层信号(“用户开始了一个对话轮次/完成了对话轮次”)。
5.2 第一层:VAD — 声音活动检测
Source: src/pipecat/audio/vad/
5.2.1 VADAnalyzer:四态状态机
VAD 的核心是一个四态状态机,通过计数确认机制避免误检:
# vad_analyzer.py:31-44
class VADState(Enum):
QUIET = 1 # 安静
STARTING = 2 # 可能开始说话(需要确认)
SPEAKING = 3 # 确认正在说话
STOPPING = 4 # 可能停止说话(需要确认)
状态转换逻辑(_run_analyzer 方法):
confidence >= threshold
QUIET ──────────────────────────────→ STARTING
↑ │
│ confidence < threshold │ 连续 start_frames 次
│ (reset counter) ▼
├────────────────────────────── SPEAKING
│ │
│ 连续 stop_frames 次 │ confidence < threshold
│ ▼
└────────────────────────────── STOPPING
confidence >= threshold │
(reset, back to SPEAKING) ←───────┘
设计决策:计数确认(Debouncing)
# vad_analyzer.py:207-244
speaking = confidence >= self._params.confidence and volume >= self._params.min_volume
if speaking:
match self._vad_state:
case VADState.QUIET:
self._vad_state = VADState.STARTING
self._vad_starting_count = 1 # 开始计数
case VADState.STARTING:
self._vad_starting_count += 1 # 继续计数
case VADState.STOPPING:
self._vad_state = VADState.SPEAKING # 取消停止,回到说话
self._vad_stopping_count = 0
# 只有连续达到阈值帧数才确认状态转换
if self._vad_state == VADState.STARTING and self._vad_starting_count >= self._vad_start_frames:
self._vad_state = VADState.SPEAKING # 确认开始说话
为什么不是简单的"检测到声音就开始"?因为:
start_secs=0.2:需要持续 200ms 的语音才确认开始,过滤掉咳嗽、键盘声等stop_secs=0.2:需要持续 200ms 的静音才确认结束,允许正常的句内停顿min_volume=0.6:额外的音量阈值,防止低音量噪声触发 VADconfidence=0.7:模型置信度阈值
帧数计算公式:
# vad_analyzer.py:161-164
vad_frames_per_sec = self._vad_frames / self.sample_rate # 一帧的时长
self._vad_start_frames = round(start_secs / vad_frames_per_sec) # 需要多少帧
self._vad_stop_frames = round(stop_secs / vad_frames_per_sec)
5.2.1.1 这段代码真正做了什么?
如果只看设计意图,VADAnalyzer 解决的问题不是“识别一句话的语义”,而是:
把连续不断到来的 PCM 字节流,切成模型能处理的固定窗口,并且把窗口级别的不稳定判断,压缩成一个稳定的语音活动状态。
从代码看,这个过程分成三步:
第一步:先累积字节,直到够一个分析窗口
# vad_analyzer.py
self._vad_buffer += buffer
num_required_bytes = self._vad_frames_num_bytes
if len(self._vad_buffer) < num_required_bytes:
return self._vad_state
这意味着:不是每次收到 transport 的一块音频就立刻跑一次 VAD。
VAD 先把数据攒起来,等长度达到 num_frames_required() 对应的字节数,才真正做一次判断。
第二步:从固定窗口里算两个信号
# vad_analyzer.py
confidence = self.voice_confidence(audio_frames)
volume = self._get_smoothed_volume(audio_frames)
self._prev_volume = volume
speaking = confidence >= self._params.confidence and volume >= self._params.min_volume
这里有两个输入信号:
confidence:VAD 模型判断“这像不像语音”的概率volume:当前音量大小,而且做了指数平滑
作者的意图很明确:不要只信模型概率,也不要只信音量,必须两者都过线。
第三步:把窗口级别判断压成状态机
# vad_analyzer.py
if speaking:
match self._vad_state:
case VADState.QUIET:
self._vad_state = VADState.STARTING
self._vad_starting_count = 1
case VADState.STARTING:
self._vad_starting_count += 1
case VADState.STOPPING:
self._vad_state = VADState.SPEAKING
self._vad_stopping_count = 0
else:
match self._vad_state:
case VADState.STARTING:
self._vad_state = VADState.QUIET
self._vad_starting_count = 0
case VADState.SPEAKING:
self._vad_state = VADState.STOPPING
self._vad_stopping_count = 1
case VADState.STOPPING:
self._vad_stopping_count += 1
这段代码的本质是:窗口判断是离散抖动的,状态机输出才是连续稳定的。
5.2.1.2 为什么还要算音量,而且要做平滑?
平滑音量的代码很短,但设计上很关键:
# vad_analyzer.py
def _get_smoothed_volume(self, audio: bytes) -> float:
volume = calculate_audio_volume(audio, self.sample_rate)
return exp_smoothing(volume, self._prev_volume, self._smoothing_factor)
作者想解决的是两个问题:
- 瞬时尖峰噪音:比如键盘、敲桌子、轻微碰撞
- 模型置信度偶发偏高:模型可能在某些非语音片段上也打出较高分
所以这里没有用“当前原始音量”直接判定,而是:
- 先算窗口音量
- 再和上一时刻的音量做指数平滑
这样一来,VAD 不会因为某个极短的脉冲噪音就立刻抖成 STARTING / SPEAKING。
5.2.1.3 start_secs / stop_secs 在代码里的精确定义
这两个参数经常被误解成“语音开始延迟”和“语音结束延迟”。更准确地说,它们表示:
在窗口级别判断已经满足 speaking / non-speaking 的情况下,还需要连续满足多久,状态机才会承认这个变化。
换句话说:
start_secs不是 transport 延迟,而是 进入SPEAKING之前的确认窗口stop_secs不是简单静音长度,而是 退出SPEAKING之前的确认窗口
所以这两个值影响的不只是 VAD 自己,还会传导到:
- turn detection 的时机
- STT finalization 的超时补偿
- 用户感知到的交互灵敏度
5.2.1.4 为什么 analyze_audio() 要跑在线程池里?
# vad_analyzer.py
async def analyze_audio(self, buffer: bytes) -> VADState:
loop = asyncio.get_running_loop()
state = await loop.run_in_executor(self._executor, self._run_analyzer, buffer)
return state
这里的意图不是“为了并行更快”,而是两个更实际的目标:
- 不阻塞 asyncio 事件循环
- 保证单个音频流上的状态机串行执行
因为:
- 模型推理和 numpy 处理都可能占用 CPU
_vad_buffer、_vad_state、计数器这些状态都不是线程安全共享结构
所以作者选的是一个折中方案:
- 每个 analyzer 一个
ThreadPoolExecutor(max_workers=1) - 既避免阻塞主事件循环
- 又保证同一条音频流的 VAD 状态按顺序推进
5.2.2 VADController:事件桥接
VADController 把 VADAnalyzer 的状态变化转换为事件:
# vad_controller.py:126-140
async def _handle_vad(self, audio: bytes, vad_state: VADState) -> VADState:
new_vad_state = await self._vad_analyzer.analyze_audio(audio)
# 只关心 SPEAKING 和 QUIET 的变化(忽略中间态 STARTING/STOPPING)
if new_vad_state != vad_state \
and new_vad_state != VADState.STARTING \
and new_vad_state != VADState.STOPPING:
if new_vad_state == VADState.SPEAKING:
await self._call_event_handler("on_speech_started")
elif new_vad_state == VADState.QUIET:
await self._call_event_handler("on_speech_stopped")
return new_vad_state
关键设计:同步事件处理器。 所有事件注册为 sync=True:
# vad_controller.py:84-88
self._register_event_handler("on_speech_started", sync=True)
self._register_event_handler("on_speech_stopped", sync=True)
self._register_event_handler("on_speech_activity", sync=True)
为什么同步?因为 VAD 事件处理器的响应(生成 VADUserStartedSpeakingFrame)需要在下一个音频帧到达之前完成,如果异步调度可能丢失时序。
5.2.2.1 VADController 到底解决了什么问题?
VADAnalyzer 只会返回一个内部状态:QUIET / STARTING / SPEAKING / STOPPING。
但 pipeline 其他处理器不能直接依赖这个内部状态对象,否则:
- 所有处理器都要懂 VAD 状态机细节
- 所有处理器都要自己处理过渡态
- 状态变化和 frame 广播逻辑会散落在各处
所以 VADController 的真正意图是:
把“VAD 内部状态变化”提升成“对外可消费的语音事件”。
从代码上看,它只做三件事:
# vad_controller.py
if isinstance(frame, StartFrame):
await self._start(frame)
elif isinstance(frame, InputAudioRawFrame):
await self._handle_audio(frame)
elif isinstance(frame, VADParamsUpdateFrame):
self._vad_analyzer.set_params(frame.params)
await self.broadcast_frame(SpeechControlParamsFrame, vad_params=frame.params)
也就是说,它是一个非常薄的 orchestration 层:
StartFrame:初始化 sample rate,并广播初始参数InputAudioRawFrame:送给 analyzer 做检测VADParamsUpdateFrame:热更新参数,并同步通知下游
5.2.2.2 为什么要忽略 STARTING / STOPPING?
这是 VADController 最重要的设计选择之一:
# vad_controller.py
if (
new_vad_state != vad_state
and new_vad_state != VADState.STARTING
and new_vad_state != VADState.STOPPING
):
if new_vad_state == VADState.SPEAKING:
await self._call_event_handler("on_speech_started")
elif new_vad_state == VADState.QUIET:
await self._call_event_handler("on_speech_stopped")
作者故意不把过渡态传播出去,原因是:
STARTING/STOPPING只是内部防抖细节,不应该成为 pipeline 级别的公共协议。
否则上层 turn strategy、STT、metrics、observer 都要理解:
- “这是真的开始了吗?”
- “这只是准备停止,还是已经停止?”
这样会把本来应该封装在 VAD 内部的复杂度泄漏出去。
所以对外只暴露两个稳定边界:
SPEAKING:确认已经开始说话QUIET:确认已经停止说话
5.2.2.3 on_speech_activity 为什么存在?
除了 started/stopped,controller 还会在 SPEAKING 状态下持续触发 activity:
# vad_controller.py
self._vad_state = await self._handle_vad(frame.audio, self._vad_state)
if self._vad_state == VADState.SPEAKING:
await self._call_event_handler("on_speech_activity")
这个事件不是“边界事件”,而是“持续活动信号”。
它的设计意图是给上层一个更轻量的提示:
- 用户还在说话
- 可以更新 UI speaking indicator
- 可以周期性发
UserSpeakingFrame - 可以供 observer/metrics 记录“讲话进行中”
所以:
on_speech_started/on_speech_stopped是边界on_speech_activity是心跳
5.2.2.4 初始参数为什么要通过 SpeechControlParamsFrame 广播?
StartFrame 时 controller 会做一件很容易被忽略的事:
# vad_controller.py
async def _start(self, frame: StartFrame):
self._vad_analyzer.set_sample_rate(frame.audio_in_sample_rate)
await self.broadcast_frame(SpeechControlParamsFrame, vad_params=self._vad_analyzer.params)
这背后的意图是:
VAD 参数不是 VAD 自己私有的,它们会影响其他依赖时序补偿的处理器。
比如:
- STT service 可能需要知道 VAD 参数做 latency/TTFB 推断
- turn analyzer 可能要根据
start_secs/stop_secs修正时间窗口
所以 VAD 初始化不是“自己 set 一下 sample rate 就结束”,而是会把参数广播成系统级控制信息。
5.2.3 VAD 实现
Pipecat 提供两种 VAD 实现:
| 实现 | 文件 | 模型 | 特点 |
|---|---|---|---|
SileroVADAnalyzer | silero.py | Silero ONNX | 独立部署,支持 8kHz/16kHz |
WebRTCVADAnalyzer | daily/transport.py | Daily 原生 WebRTC VAD | 依赖 Daily SDK |
AICVADAnalyzer | aic_vad.py | AIC SDK | 延迟绑定工厂模式 |
线程模型: VAD 模型推理在独立的 ThreadPoolExecutor(max_workers=1) 中运行:
# vad_analyzer.py:91,186-188
self._executor = ThreadPoolExecutor(max_workers=1)
async def analyze_audio(self, buffer: bytes) -> VADState:
loop = asyncio.get_running_loop()
state = await loop.run_in_executor(self._executor, self._run_analyzer, buffer)
return state
这保证了 VAD 推理不会阻塞事件循环,同时单线程保证了状态一致性。
5.2.3.1 默认实现 SileroVADAnalyzer 具体怎么跑?
默认最常见的是 SileroVADAnalyzer。它实现了 voice_confidence(),也就是:
给固定长度的 PCM 窗口,返回一个“像不像语音”的置信度。
关键代码在 silero.py:
# silero.py
def voice_confidence(self, buffer) -> float:
audio_int16 = np.frombuffer(buffer, np.int16)
audio_float32 = np.frombuffer(audio_int16, dtype=np.int16).astype(np.float32) / 32768.0
new_confidence = self._model(audio_float32, self.sample_rate)[0]
...
return new_confidence
这段代码做了三件事:
- 把
bytes解释成 int16 PCM - 归一化到
[-1, 1]的 float32 - 喂给 Silero ONNX 模型,拿到概率值
也就是说,SileroVADAnalyzer 并不直接发 frame,它只负责:
PCM bytes -> confidence
真正的状态稳定化仍然由 VADAnalyzer 基类完成。
5.2.3.2 为什么 num_frames_required() 固定成 512 / 256?
# silero.py
def num_frames_required(self) -> int:
return 512 if self.sample_rate == 16000 else 256
这不是随便选的 chunk 大小,而是 Silero 模型输入规格。
对应关系是:
- 16kHz 输入时,每次要 512 个 sample
- 8kHz 输入时,每次要 256 个 sample
所以 VADAnalyzer 里的 _vad_buffer 本质上是在做一件事:
把 transport 下游传来的任意大小音频块,重新拼接成 VAD 模型所要求的固定窗口。
5.2.3.3 为什么模型状态要周期性 reset?
Silero 实现里还有一个很关键的小细节:
# silero.py
if diff_time >= _MODEL_RESET_STATES_TIME:
self._model.reset_states()
self._last_reset_time = curr_time
这里的设计意图不是为了“让模型更准”,而是为了工程稳定性:
- Silero ONNX 模型内部维护上下文状态
- 长时间连续运行可能会让内部状态和内存持续累积
所以作者每隔一段时间主动 reset 一次,目的是:
- 避免长期运行时状态漂移
- 控制资源占用
- 保持服务型场景下的稳定性
5.2.4 从 VAD 事件到关键 Frame:谁在发 VADUserStartedSpeakingFrame?
这一层不在 audio/vad/ 目录里,而是在 LLMUserAggregator 里完成。
LLMUserAggregator.process_frame() 每收到一个 frame,都会先把音频交给 VADController:
# llm_response_universal.py
if self._vad_controller:
await self._vad_controller.process_frame(frame)
然后 aggregator 通过 event handler,把 VAD 事件包装成真正流进 pipeline 的 frame:
# llm_response_universal.py
async def _on_vad_speech_started(self, controller):
await self._queued_broadcast_frame(
VADUserStartedSpeakingFrame,
start_secs=controller._vad_analyzer.params.start_secs,
)
async def _on_vad_speech_stopped(self, controller):
await self._queued_broadcast_frame(
VADUserStoppedSpeakingFrame,
stop_secs=controller._vad_analyzer.params.stop_secs,
)
async def _on_vad_speech_activity(self, controller):
await self._queued_broadcast_frame(UserSpeakingFrame)
这说明:
VADAnalyzer不发 frameVADController也不直接发 frame 对象,它只发事件- 真正把事件翻译成 frame 的,是聚合器这一层
作者这样拆的意图是:
把底层检测逻辑和 pipeline 协议解耦。
如果以后更换 VAD 实现,只要还能触发同样的 started/stopped/activity 事件,上层 frame 协议完全不需要变。
5.2.4.1 为什么是 _queued_broadcast_frame() 而不是直接 push_frame()?
_queued_broadcast_frame() 会做两件事:
- 把 frame 排队给自己内部再处理一次
- 同时把 frame 向 upstream 广播出去
对应代码:
# llm_response_universal.py
async def _queued_broadcast_frame(self, frame_cls: Type[Frame], **kwargs):
await self._internal_queue_frame(frame_cls(**kwargs))
await self.push_frame(frame_cls(**kwargs), FrameDirection.UPSTREAM)
它的意图是:
- 对外:让 pipeline 其他处理器立刻收到
VADUserStartedSpeakingFrame - 对内:让 aggregator 自己的
UserTurnController也走一遍同样的 frame 流程
这样整个系统看到的是统一的 frame 流,而不是“有些状态只存在于对象内部,有些状态才发进 pipeline”。
5.2.4.2 VAD 最终发出的关键 frame 有哪些?
从代码看,VAD 直接相关的关键 frame 有三类:
| Frame | 谁发出 | 含义 |
|---|---|---|
VADUserStartedSpeakingFrame | LLMUserAggregator | 原始 VAD 已确认进入 SPEAKING |
VADUserStoppedSpeakingFrame | LLMUserAggregator | 原始 VAD 已确认回到 QUIET |
UserSpeakingFrame | LLMUserAggregator | 用户当前仍在说话中的活动心跳 |
这些 frame 的语义是物理层的,不是最终对话轮次:
- 它们表示“检测到语音活动”
- 不表示“用户的一轮输入已经开始/结束”
真正的语义层 frame 是后续策略层发出的:
UserStartedSpeakingFrameUserStoppedSpeakingFrame
所以可以把整个 VAD 链路理解为:
InputAudioRawFrame
-> VADAnalyzer (confidence + volume + state machine)
-> VADController (started/stopped/activity events)
-> LLMUserAggregator (wrap into VAD frames)
-> UserTurnController / strategies
-> semantic user turn frames
5.3 第二层:Turn Start 策略 — 决定何时开始轮次
Source: src/pipecat/turns/user_start/
Turn Start 策略回答一个问题:用户是否开始了一个新的对话轮次?
5.3.1 策略基类
# base_user_turn_start_strategy.py
class BaseUserTurnStartStrategy(BaseObject):
def __init__(self, *, enable_interruptions=True, enable_user_speaking_frames=True):
# enable_interruptions: 触发时是否中断当前 bot 输出
# enable_user_speaking_frames: 是否广播 UserStartedSpeakingFrame
async def process_frame(self, frame: Frame):
"""子类重写,判断是否触发 turn start"""
pass
async def trigger_user_turn_started(self):
"""触发 on_user_turn_started 事件,携带参数"""
await self._call_event_handler("on_user_turn_started",
UserTurnStartedParams(
enable_interruptions=self._enable_interruptions,
enable_user_speaking_frames=self._enable_user_speaking_frames,
))
5.3.2 四种内置策略
1. VADUserTurnStartStrategy — 最常用,VAD 触发即开始
# vad_user_turn_start_strategy.py — 完整实现仅 ~10 行
class VADUserTurnStartStrategy(BaseUserTurnStartStrategy):
async def process_frame(self, frame: Frame):
await super().process_frame(frame)
if isinstance(frame, VADUserStartedSpeakingFrame):
await self.trigger_user_turn_started()
逻辑极简:VAD 说开始了,Turn 就开始了。这是默认的第一策略。
2. TranscriptionUserTurnStartStrategy — 后备策略,STT 检测到文字即开始
当 VAD 未检测到语音但 STT 返回了转录时作为后备触发。例如:音量太低未达到 VAD 阈值,但 STT 仍然识别出了文字。这是默认的第二策略。
3. MinWordsUserTurnStartStrategy — 需要最少单词数
需要至少 N 个单词才触发开始。适用于需要防止单字误触发的场景。
4. ExternalUserTurnStartStrategy — 外部控制
等待外部组件推送 UserStartedSpeakingFrame。禁用中断和 speaking 帧。用于由 STT 服务或其他外部组件直接控制轮次的场景。
5.3.3 默认策略组合
# user_turn_strategies.py:46-50
class UserTurnStrategies:
def __post_init__(self):
if not self.start:
self.start = [VADUserTurnStartStrategy(), TranscriptionUserTurnStartStrategy()]
if not self.stop:
self.stop = [TurnAnalyzerUserTurnStopStrategy(turn_analyzer=LocalSmartTurnAnalyzerV3())]
默认组合 = VAD 优先 + STT 后备。两个策略同时运行,任何一个触发就算开始(first-wins 语义)。
5.4 第三层:Turn Stop 策略 — 决定何时结束轮次
Source: src/pipecat/turns/user_stop/
Turn Stop 是整个系统中最复杂的部分。它需要回答一个很难的问题:用户是真的说完了,还是只是在停顿?
5.4.1 TurnAnalyzerUserTurnStopStrategy — 基于 ML 模型的轮次结束检测
这是默认的 stop 策略,使用机器学习模型判断用户是否说完。
核心状态变量:
# turn_analyzer_user_turn_stop_strategy.py
self._turn_analyzer = turn_analyzer # ML 模型
self._stt_timeout: float = 0.0 # STT P99 延迟(从 STTMetadataFrame 获取)
self._stop_secs: float = 0.0 # VAD stop_secs
self._text = "" # 累积的转录文本
self._turn_complete = False # 模型是否判断 turn 完成
self._vad_user_speaking = False # VAD 是否检测到语音
self._transcript_finalized = False # 是否收到 finalized transcript
处理流程:
VADUserStartedSpeaking ──→ 重置状态,取消超时
vad_user_speaking = True
InputAudioRawFrame ──────→ turn_analyzer.append_audio(audio, is_speech)
如果流式模型返回 COMPLETE → turn_complete = True
VADUserStoppedSpeaking ──→ vad_user_speaking = False
turn_analyzer.analyze_end_of_turn()
如果批量模型返回 COMPLETE → turn_complete = True
启动 STT 超时任务 (timeout = stt_timeout - stop_secs)
TranscriptionFrame ──────→ text = frame.text
如果 finalized → transcript_finalized = True
→ _maybe_trigger_user_turn_stopped()
超时到达 ────────────────→ _maybe_trigger_user_turn_stopped()
触发条件(_maybe_trigger_user_turn_stopped):
# turn_analyzer_user_turn_stop_strategy.py:205-227
async def _maybe_trigger_user_turn_stopped(self):
# 必须有转录文本 AND 模型判断 turn 完成
if not self._text or not self._turn_complete:
return
# finalized transcript → 立即触发
if self._transcript_finalized:
await self.trigger_user_turn_stopped()
return
# 非 finalized → 只在超时任务完成后触发
if self._timeout_task is None:
await self.trigger_user_turn_stopped()
超时补偿设计:
# turn_analyzer_user_turn_stop_strategy.py:155-159
# VAD 的 stop_secs 已经过去了(那段时间是 VAD 在等待确认静音)
# 所以 STT 超时需要减去这段时间
timeout = max(0, self._stt_timeout - self._stop_secs)
为什么要减去 stop_secs?时间线:
用户实际停止说话
│
├── stop_secs (0.2s) ──→ VAD 确认静音,发出 VADUserStoppedSpeaking
│ │
│ ├── (stt_timeout - stop_secs) ──→ 超时触发
如果不减,超时等待会过长,因为 VAD 确认静音时 STT 已经在处理了。
5.4.2 SpeechTimeoutUserTurnStopStrategy — 基于超时的简单策略
不使用 ML 模型,纯基于时间:
# speech_timeout_user_turn_stop_strategy.py:145-158
def _calculate_timeout(self) -> float:
effective_stt_wait = max(0, self._stt_timeout - self._stop_secs)
if self._transcript_finalized:
return self._user_speech_timeout # 已有最终转录,只等用户恢复说话
return max(effective_stt_wait, self._user_speech_timeout) # 取大值
user_speech_timeout=0.6s 是给用户的"恢复说话窗口"。如果在这段时间内用户又开始说话(VAD 触发),超时任务会被取消。
5.4.3 ExternalUserTurnStopStrategy
等待外部 UserStoppedSpeakingFrame,与 ExternalUserTurnStartStrategy 配套使用。
5.4.4 BaseTurnAnalyzer — ML 模型接口
# audio/turn/base_turn_analyzer.py
class BaseTurnAnalyzer(ABC):
@abstractmethod
def append_audio(self, buffer: bytes, is_speech: bool) -> EndOfTurnState:
"""逐帧添加音频。流式分析器可能在此返回 COMPLETE。"""
@abstractmethod
async def analyze_end_of_turn(self) -> Tuple[EndOfTurnState, Optional[MetricsData]]:
"""批量分析是否 turn 完成。在 VAD 停止时调用。"""
def update_vad_start_secs(self, vad_start_secs: float):
"""同步 VAD 的 start 延迟,调整预缓冲大小。"""
两种分析模式:
| 模式 | 代表实现 | append_audio | analyze_end_of_turn | 特点 |
|---|---|---|---|---|
| 流式 | KrispVivaTurn | 返回 COMPLETE | 确认 | 实时逐帧判断 |
| 批量 | LocalSmartTurnAnalyzerV3 | 总是 INCOMPLETE | 返回结果 | VAD 停止时一次性分析 |
默认使用 LocalSmartTurnAnalyzerV3(本地 ML 模型,V3 版本)。
5.5 UserTurnController — 策略编排器
Source: src/pipecat/turns/user_turn_controller.py
Controller 负责协调所有策略,管理轮次状态,防止重复触发:
# user_turn_controller.py
class UserTurnController(BaseObject):
def __init__(self, *, user_turn_strategies, user_turn_stop_timeout=5.0):
self._user_turn = False # 当前是否在一个轮次中
self._user_speaking = False # 用户是否正在说话
核心调度逻辑:
# user_turn_controller.py:141-167
async def process_frame(self, frame: Frame):
# 1. 先处理 VAD/User speaking 状态(重置超时)
if isinstance(frame, UserStartedSpeakingFrame):
self._user_speaking = True
self._user_turn_stop_timeout_event.set() # 重置超时
elif isinstance(frame, VADUserStartedSpeakingFrame):
self._user_speaking = True
self._user_turn_stop_timeout_event.set()
# ... 类似处理 stopped 和 transcription
# 2. 分发给所有 start 策略
for strategy in self._user_turn_strategies.start or []:
await strategy.process_frame(frame)
# 3. 分发给所有 stop 策略
for strategy in self._user_turn_strategies.stop or []:
await strategy.process_frame(frame)
防重复触发:
# user_turn_controller.py:245-259
async def _trigger_user_turn_start(self, strategy, params):
if self._user_turn: # 已经在轮次中,忽略
return
self._user_turn = True
# 重置所有 start 策略
for s in self._user_turn_strategies.start or []:
await s.reset()
await self._call_event_handler("on_user_turn_started", strategy, params)
async def _trigger_user_turn_stop(self, strategy, params):
if not self._user_turn: # 不在轮次中,忽略
return
self._user_turn = False
# 重置所有 stop 策略
for s in self._user_turn_strategies.stop or []:
await s.reset()
await self._call_event_handler("on_user_turn_stopped", strategy, params)
超时保护:
# user_turn_controller.py:277-290
async def _user_turn_stop_timeout_task_handler(self):
while True:
try:
await asyncio.wait_for(
self._user_turn_stop_timeout_event.wait(),
timeout=self._user_turn_stop_timeout, # 默认 5.0s
)
self._user_turn_stop_timeout_event.clear()
except asyncio.TimeoutError:
# 5秒内没有任何活动 → 强制结束轮次
if self._user_turn and not self._user_speaking:
await self._trigger_user_turn_stop(None, UserTurnStoppedParams(...))
超时事件(_user_turn_stop_timeout_event)在以下情况重置:
- 用户开始/停止说话
- VAD 开始/停止
- 收到转录
如果 5 秒内都没有上述活动且用户不在说话 → 自动结束轮次。
5.6 UserTurnProcessor — FrameProcessor 包装
Source: src/pipecat/turns/user_turn_processor.py
将 Controller 包装为 FrameProcessor,接入管道:
# user_turn_processor.py:115-147
async def process_frame(self, frame: Frame, direction: FrameDirection):
await super().process_frame(frame, direction)
# 1. 先推送帧给下游(StartFrame/EndFrame 必须先到达所有处理器)
if isinstance(frame, StartFrame):
await self.push_frame(frame, direction)
await self._start(frame) # 初始化 controller
elif isinstance(frame, EndFrame):
await self.push_frame(frame, direction)
await self._stop(frame)
else:
await self.push_frame(frame, direction)
# 2. 交给 controller 处理
await self._user_turn_controller.process_frame(frame)
# 3. 交给 idle controller 处理
await self._user_idle_controller.process_frame(frame)
事件处理:当 turn start 触发时
# user_turn_processor.py:171-187
async def _on_user_turn_started(self, controller, strategy, params):
# 1. 广播 UserStartedSpeakingFrame(如果策略允许)
if params.enable_user_speaking_frames:
await self.broadcast_frame(UserStartedSpeakingFrame)
# 2. 中断当前 bot 输出(如果策略允许且处理器允许)
if params.enable_interruptions and self._allow_interruptions:
await self.broadcast_interruption()
# 3. 触发外部事件
await self._call_event_handler("on_user_turn_started", strategy)
5.7 UserIdleController — 用户闲置检测
Source: src/pipecat/turns/user_idle_controller.py
检测用户在 bot 说完后长时间不说话的场景:
# user_idle_controller.py:95-136
async def process_frame(self, frame: Frame):
if isinstance(frame, BotStoppedSpeakingFrame):
# Bot 说完了 → 启动闲置计时器
# 但要排除:用户正在说话(中断场景)、function call 进行中
if not self._user_turn_in_progress and self._function_calls_in_progress == 0:
await self._start_idle_timer()
elif isinstance(frame, BotStartedSpeakingFrame):
await self._cancel_idle_timer() # Bot 又开始说了
elif isinstance(frame, UserStartedSpeakingFrame):
self._user_turn_in_progress = True
await self._cancel_idle_timer() # 用户开始说了
elif isinstance(frame, FunctionCallsStartedFrame):
self._function_calls_in_progress += len(frame.function_calls)
await self._cancel_idle_timer() # Function call 开始了
典型用途:用户闲置 10 秒后推送一个提示语(“Are you still there?")。
5.8 完整数据流时间线
一个典型的用户-bot 对话轮次:
时间 ─────────────────────────────────────────────────→
[音频输入] ░░░░░████████████████████░░░░░░░░░░░░░░░░░
↑ ↑
│ │
[VAD] STARTING→SPEAKING STOPPING→QUIET
│(200ms确认) │(200ms确认)
▼ ▼
[VAD Frame] VADUserStartedSpeaking VADUserStoppedSpeaking
│ │
[Start策略] │ │
VAD策略 ─────→ trigger_turn_started │
│ │
[Controller] _user_turn=True │
reset all start策略 │
│ │
[Processor] broadcast(UserStartedSpeaking) │
broadcast_interruption() │
│ │
[Stop策略] │ │
TurnAnalyzer │← append_audio(每帧) → analyze_end_of_turn()
│ │ turn_complete?
│ │ start timeout(stt_timeout - stop_secs)
│ │
[STT] InterimTranscription... TranscriptionFrame (finalized)
│
[Stop策略] _maybe_trigger_user_turn_stopped()
text有 && turn_complete → 触发!
│
[Controller] _user_turn=false
reset all stop策略
│
[Processor] broadcast(UserStoppedSpeakingFrame)
│
[LLM Aggregator] 收集完成,触发 LLM 调用
5.9 设计洞察
为什么是策略模式而不是单一算法?
不同场景需要完全不同的轮次检测:
- 普通对话 → VAD + ML 模型(默认)
- 电话 IVR → 超时策略(简单可靠)
- 多模态 → 外部策略(由视觉或其他信号控制)
- 文本输入 → 无需 VAD,直接由转录触发
策略模式让这些场景可以通过组合不同策略来实现,而不是修改核心逻辑。
Start 和 Stop 的不对称性
Start 策略极其简单(几行代码),Stop 策略极其复杂(200+ 行)。这反映了问题本身的不对称性:
- 开始说话:检测到声音就行,代价低(最多中断一下 bot)
- 结束说话:判断错误代价高(过早 → bot 抢话,过晚 → 延迟太高)
所以 Stop 策略需要综合 VAD、ML 模型、STT 超时、transcript finalization 等多个信号。
VAD stop_secs 补偿贯穿整个系统
stop_secs(VAD 确认静音的等待时间)在多处被用于时间补偿:
TurnAnalyzerUserTurnStopStrategy:timeout = stt_timeout - stop_secsSpeechTimeoutUserTurnStopStrategy:effective_stt_wait = stt_timeout - stop_secsUserBotLatencyObserver:user_stopped_time = frame.timestamp - frame.stop_secs
这是因为 VAD 确认静音时,那段静音时间已经过去了——STT 可能已经在处理了。
5.10 VAD 模型实现深度解析
5.10.1 Silero VAD — ONNX 模型推理
Source: src/pipecat/audio/vad/silero.py
Silero VAD 是 Pipecat 的默认 VAD 实现,使用预训练的 ONNX 模型进行语音活动检测。
模型架构:
# silero.py:34-127 — SileroOnnxModel
class SileroOnnxModel:
def __init__(self, path, force_onnx_cpu=True):
opts = onnxruntime.SessionOptions()
opts.inter_op_num_threads = 1 # 单线程推理
opts.intra_op_num_threads = 1
self.session = onnxruntime.InferenceSession(path, providers=["CPUExecutionProvider"])
self.reset_states()
self.sample_rates = [8000, 16000] # 只支持这两种采样率
def __call__(self, x, sr: int):
"""每次处理固定大小的帧"""
num_samples = 512 if sr == 16000 else 256 # 32ms @ 16kHz 或 32ms @ 8kHz
# 关键:模型维护内部状态(RNN 隐状态 + 上下文缓冲)
context_size = 64 if sr == 16000 else 32
x = np.concatenate((self._context, x), axis=1) # 拼接上下文
ort_inputs = {"input": x, "state": self._state, "sr": np.array(sr, dtype="int64")}
ort_outs = self.session.run(None, ort_inputs)
out, state = ort_outs
self._state = state # 更新 RNN 隐状态
self._context = x[..., -context_size:] # 保留上下文尾部
return out # 置信度值 [0, 1]
关键设计细节:
- 固定帧大小:16kHz 时每帧 512 采样点(32ms),8kHz 时 256 采样点。这决定了
VADAnalyzer的num_frames_required()返回值 - 有状态推理:模型内部维护 RNN 隐状态
_state(shape:[2, 1, 128])和上下文缓冲_context。每次推理都依赖前一次的状态,所以不能并发调用 - 周期性状态重置:每 5 秒重置一次模型状态,防止内存无限增长:
# silero.py:216-219
_MODEL_RESET_STATES_TIME = 5.0
curr_time = time.time()
if diff_time >= _MODEL_RESET_STATES_TIME:
self._model.reset_states()
数据流转换链:
原始音频 (PCM int16 bytes)
│
▼ np.frombuffer(buffer, np.int16)
int16 数组
│
▼ .astype(np.float32) / 32768.0
float32 数组 [-1.0, 1.0]
│
▼ model(audio_float32, sample_rate)
置信度 float [0.0, 1.0]
│
▼ VADAnalyzer._run_analyzer() 状态机判断
VADState (QUIET | STARTING | SPEAKING | STOPPING)
5.10.2 VADAnalyzer 缓冲机制
VADAnalyzer.analyze_audio() 不是每收到一帧音频就分析一次。它维护一个内部缓冲区,积累到足够的帧数后才调用模型:
# vad_analyzer.py:190-200
def _run_analyzer(self, buffer: bytes) -> VADState:
self._vad_buffer += buffer # 追加到内部缓冲
num_required_bytes = self._vad_frames_num_bytes # 512*2=1024 bytes @ 16kHz
if len(self._vad_buffer) < num_required_bytes:
return self._vad_state # 不够一帧,返回当前状态
# 可能积累了多帧(如果上游给了大 chunk),逐帧处理
while len(self._vad_buffer) >= num_required_bytes:
audio_frames = self._vad_buffer[:num_required_bytes]
self._vad_buffer = self._vad_buffer[num_required_bytes:]
confidence = self.voice_confidence(audio_frames) # 调用模型
volume = self._get_smoothed_volume(audio_frames)
# ... 状态机转换逻辑 ...
音量平滑过滤: 除了模型置信度,还使用指数平滑的音量作为额外信号:
# vad_analyzer.py:207
speaking = confidence >= self._params.confidence and volume >= self._params.min_volume
双条件确保:即使模型给出高置信度,如果音量太低(如风扇噪声恰好有语音特征),也不会误触发。
5.10.3 VADController 的帧生成时序
VADController 不直接生成帧——它触发 sync=True 的事件,由注册在事件上的处理器(UserTurnProcessor)来生成帧:
InputAudioRawFrame
│
▼
VADController._handle_audio()
│
▼
VADAnalyzer.analyze_audio() → VADState
│
├─ SPEAKING (从 QUIET/STARTING 变为) → _call_event_handler("on_speech_started")
│ ↓ (sync=True, 立即执行)
│ UserTurnProcessor 注册的 handler
│ ↓
│ broadcast_frame(VADUserStartedSpeakingFrame)
│ broadcast_frame(SpeechActivityFrame)
│
└─ QUIET (从 SPEAKING/STOPPING 变为) → _call_event_handler("on_speech_stopped")
↓ (sync=True, 立即执行)
UserTurnProcessor 注册的 handler
↓
broadcast_frame(VADUserStoppedSpeakingFrame)
为什么 sync=True 至关重要? 如果事件是异步的(默认),handler 会在独立的 Task 中执行。这意味着当下一个音频帧到达时,上一个帧的 VAD 事件可能还没来得及触发。对于需要精确时序的 turn detection 来说,这种延迟是不可接受的。
5.11 STT 转录流与 Finalization 机制
5.11.1 STT 服务基类架构
Source: src/pipecat/services/stt_service.py
STT 服务有三种基类,适用于不同的语音转文字模式:
AIService
└── STTService # 连续流式 STT(如 Deepgram WebSocket)
├── SegmentedSTTService # 分段式 STT(VAD 分段后批量处理)
└── WebsocketSTTService # WebSocket 连接管理 + STTService
| 基类 | 音频处理方式 | finalized 机制 | 典型服务 |
|---|---|---|---|
STTService | 连续流式,每个 AudioRawFrame 都送给 run_stt() | 需要服务端确认(request_finalize / confirm_finalize) | Deepgram, AssemblyAI, Soniox |
SegmentedSTTService | VAD 分段后批量处理,用户停止说话时才送音频 | 每个 TranscriptionFrame 自动 finalized=True | Whisper, 离线批量 STT |
WebsocketSTTService | 同 STTService,额外管理 WebSocket 连接生命周期和 keepalive | 同 STTService | Deepgram, Speechmatics |
5.11.2 音频处理流程
# stt_service.py:330-383 — process_frame()
async def process_frame(self, frame: Frame, direction: FrameDirection):
if isinstance(frame, StartFrame):
await self.push_frame(frame, direction)
await self._push_stt_metadata() # ★ 广播 STTMetadataFrame
elif isinstance(frame, AudioRawFrame):
await self.process_audio_frame(frame, direction) # 送给 run_stt()
if self._audio_passthrough:
await self.push_frame(frame, direction) # 透传音频给下游
elif isinstance(frame, VADUserStartedSpeakingFrame):
await self._handle_vad_user_started_speaking(frame)
await self.push_frame(frame, direction)
elif isinstance(frame, VADUserStoppedSpeakingFrame):
await self._handle_vad_user_stopped_speaking(frame)
await self.push_frame(frame, direction)
关键观察:audio_passthrough=True(默认)。 STT 服务处理完音频后仍然把 AudioRawFrame 推送给下游。这是因为 Turn Detection 模型(TurnAnalyzerUserTurnStopStrategy)也需要原始音频作为输入。如果 STT 吞掉了音频帧,turn detection 就无法工作。
5.11.3 TranscriptionFrame 与 Finalization
转录帧有两种类型:
# frames.py
@dataclass
class InterimTranscriptionFrame(TextFrame):
"""部分/中间转录结果,随着用户说话持续更新"""
text: str
user_id: str
timestamp: str
@dataclass
class TranscriptionFrame(TextFrame):
"""最终转录结果"""
user_id: str
timestamp: str
finalized: bool = False # ★ 核心字段
finalized 的语义: 当 finalized=True 时,表示 STT 服务确认这段语音的转录已经完成。Turn Stop 策略可以立即触发,而不需要等待 STT 超时。
Finalization 的两种路径:
路径 1:服务端确认(连续流式 STT)
# stt_service.py:158-181
def request_finalize(self):
"""标记已发送 finalize 请求"""
self._finalize_requested = True
def confirm_finalize(self):
"""服务端确认 finalize"""
if self._finalize_requested:
self._finalize_pending = True
self._finalize_requested = False
# 在 push_frame 中自动标记
async def push_frame(self, frame: Frame, direction=...):
if isinstance(frame, TranscriptionFrame):
if self._finalize_pending:
frame.finalized = True # ★ 自动标记
self._finalize_pending = False
例如 Deepgram:用户停止说话时,发送 finalize 命令;Deepgram 返回最终转录并在元数据中设置 from_finalize=True;STT 服务调用 confirm_finalize();下一个 TranscriptionFrame 被标记为 finalized。
路径 2:自动标记(分段式 STT)
# stt_service.py:597-609 — SegmentedSTTService.push_frame()
async def push_frame(self, frame, direction=...):
if isinstance(frame, TranscriptionFrame):
frame.finalized = True # ★ 分段 STT 的每个转录都是 finalized
await super().push_frame(frame, direction)
分段式 STT 在用户停止说话后才处理音频,所以每次返回的转录天然就是最终结果。
5.11.4 STTMetadataFrame — 延迟特征广播
# stt_service.py:414-420
async def _push_stt_metadata(self):
ttfs = self._ttfs_p99_latency
if ttfs is None:
ttfs = DEFAULT_TTFS_P99 # 1.0 秒(保守默认值)
await self.broadcast_frame(STTMetadataFrame, service_name=self.name, ttfs_p99_latency=ttfs)
在 StartFrame 时广播,告知下游处理器此 STT 服务的延迟特征。 Turn Stop 策略用这个值来计算超时:
# turn_analyzer_user_turn_stop_strategy.py:99
if isinstance(frame, STTMetadataFrame):
self._stt_timeout = frame.ttfs_p99_latency
各 STT 服务的实测 P99 TTFS 延迟:
| 服务 | TTFS P99 (秒) | 特点 |
|---|---|---|
| Deepgram | 0.35 | 最快,支持 finalize |
| Soniox | 0.35 | 与 Deepgram 并列最快 |
| AssemblyAI | 0.42 | 快速 |
| ElevenLabs Realtime | 0.41 | 实时模式 |
| Speechmatics | 0.74 | 中等 |
| Cartesia | 0.81 | 中等 |
| Sarvam | 1.17 | 较慢 |
| Gladia | 1.49 | 较慢 |
| 1.57 | 较慢 | |
| Azure | 1.80 | 慢 |
| AWS Transcribe | 1.90 | 慢 |
| OpenAI | 2.01 | 慢 |
| SambaNova | 2.20 | 最慢 |
为什么这些数字如此重要? TTFS P99 直接影响用户体验中的 “bot 响应延迟”。以 Deepgram (0.35s) vs AWS Transcribe (1.90s) 为例:
用户停止说话后...
Deepgram: 0.35s 后收到最终转录 → 触发 LLM → 总延迟 ≈ 0.35 + LLM时间
AWS: 1.90s 后收到最终转录 → 触发 LLM → 总延迟 ≈ 1.90 + LLM时间
这 1.55 秒的差距在对话中非常明显。
5.11.5 STT TTFB 测量机制
STT 服务还测量自身的"首字节时间”(TTFB),但 STT 的 TTFB 定义不同于传统 HTTP:
# stt_service.py:99-104 — 注释说明
# STT "TTFB" differs from traditional TTFB (which measures from a discrete
# request to first response byte). Since STT receives continuous audio, we measure
# from when the user stops speaking to when the final transcript arrives—capturing
# the latency that matters for voice AI applications.
测量流程:
VADUserStoppedSpeaking
│
├── speech_end_time = timestamp - stop_secs # 真实停止时间(补偿 VAD 延迟)
├── start_ttfb_metrics(start_time=speech_end_time)
└── 启动 _ttfb_timeout_handler (2.0s 超时)
│
├── 如果收到 finalized TranscriptionFrame → 立即 stop_ttfb_metrics()
└── 如果超时 → 用 _last_transcript_time 作为结束时间 stop_ttfb_metrics()
5.12 Turn Detection 模型实现深度解析
5.12.1 BaseSmartTurn — 批量分析器基础
Source: src/pipecat/audio/turn/smart_turn/base_smart_turn.py
BaseSmartTurn 是所有基于 ML 的 Smart Turn 分析器的基类,实现了音频缓冲、语音段提取、静音超时三大核心功能。
音频缓冲机制:
# base_smart_turn.py:101-147
def append_audio(self, buffer: bytes, is_speech: bool) -> EndOfTurnState:
# 转换为 float32 并追加到带时间戳的缓冲区
audio_float32 = np.frombuffer(buffer, dtype=np.int16).astype(np.float32) / 32768.0
self._audio_buffer.append((time.time(), audio_float32))
if is_speech:
self._silence_ms = 0
self._speech_triggered = True
if self._speech_start_time == 0:
self._speech_start_time = time.time()
else:
if self._speech_triggered:
chunk_duration_ms = len(audio_int16) / (self._sample_rate / 1000)
self._silence_ms += chunk_duration_ms
# ★ 静音超过阈值(默认 3 秒)→ 直接判定为 COMPLETE
if self._silence_ms >= self._stop_ms:
state = EndOfTurnState.COMPLETE
self._clear(state)
else:
# 语音开始前,限制缓冲区大小防止无限增长
max_buffer_time = pre_speech_ms/1000 + stop_secs + max_duration_secs
while self._audio_buffer[0][0] < time.time() - max_buffer_time:
self._audio_buffer.pop(0)
缓冲区设计: 每个元素是 (timestamp, audio_chunk) 元组。时间戳用于后续提取语音段时的精确定位。在语音开始之前,缓冲区大小被限制在 pre_speech_ms + stop_secs + max_duration_secs 内,防止长时间静音导致内存溢出。
语音段提取逻辑(_process_speech_segment):
# base_smart_turn.py:181-248
def _process_speech_segment(self, audio_buffer):
# 1. 计算有效的预语音缓冲时间(加上 VAD 启动延迟)
effective_pre_speech_ms = self._params.pre_speech_ms + (self._vad_start_secs * 1000)
# 500ms(默认) + 200ms(VAD start_secs)= 700ms
# 2. 从 speech_start_time 往前取 effective_pre_speech_ms 的音频
start_time = self._speech_start_time - (effective_pre_speech_ms / 1000)
# 在缓冲区中找到对应位置...
# 3. 拼接音频段
segment_audio = np.concatenate(segment_audio_chunks)
# 4. 限制最大时长(默认 8 秒,取尾部)
max_samples = int(self._params.max_duration_secs * self.sample_rate)
if len(segment_audio) > max_samples:
segment_audio = segment_audio[-max_samples:] # ★ 保留最后 8 秒
# 5. 调用子类的 ML 模型
result = self._predict_endpoint(segment_audio)
state = EndOfTurnState.COMPLETE if result["prediction"] == 1 else EndOfTurnState.INCOMPLETE
为什么取最后 8 秒? Turn Detection 模型关注的是"当前说话内容是否已经说完",而不是"用户说了什么"。最后 8 秒的音频包含了最近的韵律变化(降调、停顿模式等),这些是判断轮次结束的关键信号。
pre_speech_ms + vad_start_secs 补偿:
实际语音开始 VAD 确认开始 (start_secs=0.2s)
│ │
─────┼────────────────────┼──────────→ 时间
│←── pre_speech_ms ──│
│←── effective_pre_speech_ms ───│
500ms + 200ms = 700ms
模型需要看到语音开始之前的一些音频(静音→语音的转换本身也是判断依据)。由于 VAD 有 start_secs 的延迟,实际的语音起点比 VAD 报告的更早,所以需要额外补偿。
两层超时:
| 超时 | 默认值 | 位置 | 用途 |
|---|---|---|---|
SmartTurnParams.stop_secs | 3.0s | BaseSmartTurn.append_audio() | 纯静音超时(无需模型判断,直接 COMPLETE) |
| STT timeout | 因服务而异 | TurnAnalyzerUserTurnStopStrategy | 等待 STT 返回转录 |
3 秒的 stop_secs 是"最后的兜底"——如果 ML 模型一直判断为 INCOMPLETE 但用户已经沉默了 3 秒,强制结束轮次。
5.12.2 LocalSmartTurnAnalyzerV3 — 本地 ONNX 推理
Source: src/pipecat/audio/turn/smart_turn/local_smart_turn_v3.py
这是默认的 Turn Detection 模型,基于 Whisper 的特征提取器 + 自定义二分类 ONNX 模型。
模型加载与配置:
# local_smart_turn_v3.py:28-81
class LocalSmartTurnAnalyzerV3(BaseSmartTurn):
def __init__(self, *, smart_turn_model_path=None, cpu_count=1, **kwargs):
# 内置模型文件
model_name = "smart-turn-v3.2-cpu.onnx"
# ONNX 推理配置
so = ort.SessionOptions()
so.execution_mode = ort.ExecutionMode.ORT_SEQUENTIAL
so.inter_op_num_threads = 1
so.intra_op_num_threads = cpu_count # 可配置 CPU 核数
so.graph_optimization_level = ort.GraphOptimizationLevel.ORT_ENABLE_ALL
# ★ Whisper 特征提取器(8 秒窗口)
self._feature_extractor = WhisperFeatureExtractor(chunk_length=8)
self._session = ort.InferenceSession(smart_turn_model_path, sess_options=so)
推理流程:
# local_smart_turn_v3.py:141-197
def _predict_endpoint(self, audio_array: np.ndarray) -> Dict[str, Any]:
# 1. 重采样到 16kHz(模型固定输入)
audio_array = self._resample_to_model_rate(audio_array) # 使用 soxr VHQ
# 2. 截断或填充到 8 秒
audio_array = truncate_audio_to_last_n_seconds(audio_array, n_seconds=8)
# > 8s → 取最后 8 秒
# < 8s → 在开头补零
# 3. Whisper 特征提取(Log-Mel Spectrogram)
inputs = self._feature_extractor(
audio_array,
sampling_rate=16000,
return_tensors="np",
padding="max_length",
max_length=8 * 16000, # 128000 个采样点
truncation=True,
do_normalize=True,
)
# 4. 准备 ONNX 输入 (Log-Mel 特征图)
input_features = inputs.input_features.squeeze(0).astype(np.float32)
input_features = np.expand_dims(input_features, axis=0) # [1, n_mels, time_steps]
# 5. ONNX 推理
outputs = self._session.run(None, {"input_features": input_features})
# 6. 解读结果(sigmoid 概率)
probability = outputs[0][0].item() # [0, 1]
prediction = 1 if probability > 0.5 else 0 # 二分类阈值
return {"prediction": prediction, "probability": probability}
完整数据变换管道:
原始音频 (PCM int16, pipeline sample rate)
│
▼ BaseSmartTurn.append_audio() → float32 / 32768.0
float32 缓冲区 [(timestamp, chunk), ...]
│
▼ _process_speech_segment() → 提取 speech_start - 700ms 到 now 的音频段
float32 音频段 (可变长度)
│
▼ _resample_to_model_rate() → soxr 高质量重采样
float32 @ 16kHz
│
▼ truncate_audio_to_last_n_seconds(8s)
float32 @ 16kHz, exactly 128000 samples
│
▼ WhisperFeatureExtractor → Log-Mel Spectrogram
float32 特征图 [1, 80, 3000] (80 mel bins, 3000 time steps)
│
▼ ONNX model inference
float32 概率值 [0, 1]
│
▼ threshold > 0.5 → prediction: 1(COMPLETE) / 0(INCOMPLETE)
EndOfTurnState
线程模型: ML 推理在 ThreadPoolExecutor(max_workers=1) 中执行:
# base_smart_turn.py:156-158
loop = asyncio.get_running_loop()
state, result = await loop.run_in_executor(
self._executor, self._process_speech_segment, self._audio_buffer
)
单线程确保了:(1) 不阻塞事件循环,(2) 缓冲区访问不会并发冲突。
5.12.3 KrispVivaTurn — 流式逐帧分析器
Source: src/pipecat/audio/turn/krisp_viva_turn.py
与 LocalSmartTurnV3 的"批量分析"不同,Krisp 采用流式逐帧分析模式。
核心差异:append_audio() 中实时判断
# krisp_viva_turn.py:243-343
def append_audio(self, buffer: bytes, is_speech: bool) -> EndOfTurnState:
# 将音频分成固定帧(默认 20ms)
frames = audio_float32.reshape(-1, self._samples_per_frame)
for frame in frames:
if is_speech:
self._speech_triggered = True
self._speech_stopped_time = None
else:
if self._speech_triggered and self._speech_stopped_time is None:
self._speech_stopped_time = time.perf_counter()
# ★ 逐帧调用 Krisp SDK 处理
prob = self._tt_session.process(frame.tolist())
if prob < 0:
continue # 模型还不够数据(需要约 100ms 预热)
self._last_probability = prob
# ★ 实时判断:语音已触发 && 概率超阈值 → COMPLETE
if self._speech_triggered and prob >= self._params.threshold:
# 计算 e2e 处理时间
if self._speech_stopped_time is not None:
self._e2e_processing_time_ms = (time.perf_counter() - self._speech_stopped_time) * 1000
state = EndOfTurnState.COMPLETE
self.clear()
break
return state
analyze_end_of_turn() 仅返回已有结果:
# krisp_viva_turn.py:351-362
async def analyze_end_of_turn(self):
# 流式分析器已经在 append_audio 中做了判断
# 这里只是返回最后状态和消费 metrics
metrics = self._last_metrics
self._last_metrics = None
return self._last_state, metrics
两种模式的对比:
| 特性 | LocalSmartTurnV3 (批量) | KrispVivaTurn (流式) |
|---|---|---|
| 判断时机 | VAD 停止说话时 | 每个音频帧实时 |
append_audio 返回 | 总是 INCOMPLETE(除 3s 静音超时) | 可能返回 COMPLETE |
analyze_end_of_turn 作用 | 核心分析逻辑 | 仅返回已有结果 |
| 底层技术 | Whisper 特征 + ONNX 分类器 | Krisp SDK (C library) |
| 延迟 | 需等 VAD 停止 + 模型推理时间 | 在 VAD 停止前就可能判定 |
| 线程 | ThreadPoolExecutor | 主线程(SDK 内部优化) |
| 适用场景 | 通用 | 需要极低延迟 |
在 TurnAnalyzerUserTurnStopStrategy 中的行为差异:
# turn_analyzer_user_turn_stop_strategy.py:114-127
async def _handle_input_audio(self, frame: InputAudioRawFrame):
state = self._turn_analyzer.append_audio(frame.audio, self._vad_user_speaking)
# ★ 流式分析器(Krisp)在这里返回 COMPLETE
if state == EndOfTurnState.COMPLETE:
_, prediction = await self._turn_analyzer.analyze_end_of_turn()
await self._handle_prediction_result(prediction)
self._turn_complete = True
await self._maybe_trigger_user_turn_stopped()
# ...
async def _handle_vad_user_stopped_speaking(self, frame):
self._vad_user_speaking = False
# ★ 批量分析器(SmartTurnV3)在这里才做实际分析
state, prediction = await self._turn_analyzer.analyze_end_of_turn()
self._turn_complete = state == EndOfTurnState.COMPLETE
# 启动 STT 超时等待转录...
5.12.4 HttpSmartTurn — 远端推理
Source: src/pipecat/audio/turn/smart_turn/http_smart_turn.py
将音频发送到远端 HTTP 服务进行 ML 推理,继承 BaseSmartTurn。
# http_smart_turn.py:107-123
def _predict_endpoint(self, audio_array: np.ndarray) -> Dict[str, Any]:
# ★ 这个方法在 ThreadPoolExecutor 中运行(从 BaseSmartTurn.analyze_end_of_turn 调用)
serialized_array = self._serialize_array(audio_array) # np.save 到 bytes
# 跨线程调用异步 HTTP 请求
loop = asyncio.get_running_loop()
future = asyncio.run_coroutine_threadsafe(
self._send_raw_request(serialized_array), loop
)
return future.result() # 阻塞等待结果
注意 asyncio.run_coroutine_threadsafe 模式: 由于 _predict_endpoint 在 ThreadPoolExecutor 中运行(不在事件循环线程),需要用 run_coroutine_threadsafe 把异步 HTTP 请求安排回事件循环,然后 .result() 阻塞等待。
超时控制:
# http_smart_turn.py:67
timeout = aiohttp.ClientTimeout(total=self._params.stop_secs) # 默认 3 秒
如果远端推理超过 3 秒,抛出 SmartTurnTimeoutException,上层 _process_speech_segment 会将其视为 EndOfTurnState.COMPLETE——理由是如果已经等了 3 秒,用户大概率已经说完了。
FalSmartTurnAnalyzer 是 HttpSmartTurn 的一个具体子类,连接 Fal.ai 的托管 smart-turn 模型(已标记为 deprecated,推荐使用本地 V3)。
5.12.5 Turn Detection 模型选择指南
需要极低延迟?
│
┌───── Yes ─────┐
│ No
▼ │
KrispVivaTurn 需要离线运行?
(流式,~20ms) │
┌── Yes ──┐
│ No
▼ │
LocalSmartTurnV3 需要自定义模型?
(批量,内置ONNX) │
┌── Yes ──┐
│ No
▼ │
HttpSmartTurn │
(远端推理) │
▼
LocalSmartTurnV3
(推荐默认)
默认配置为什么选 LocalSmartTurnV3:
# user_turn_strategies.py:50
self.stop = [TurnAnalyzerUserTurnStopStrategy(turn_analyzer=LocalSmartTurnAnalyzerV3())]
- 零外部依赖:ONNX 模型内置在 package 中,无需网络、无需 API key
- 合理的精度/延迟权衡:Whisper 特征提取器提供了强大的音频表征能力
- 单线程 CPU 推理:不需要 GPU,适合大多数部署环境
- V3.2 版本:最新迭代,针对对话场景优化
5.13 与官方 Documentation Index 对照阅读
如果你是从官方文档入口继续深挖,这一节可以把「文档概念」和「源码落点」对齐起来。
官方文档建议先从 https://docs.pipecat.ai/llms.txt 看完整索引,再顺着以下主题阅读:
| 官方文档主题 | 文档侧重点 | 源码中的真实落点 |
|---|---|---|
| Speech Input & Turn Detection | 解释 VAD、turn start、turn stop 的职责分层 | audio/vad/、turns/user_start/、turns/user_stop/、turns/user_turn_controller.py |
| User Turn Strategies | 列出可配置的 start/stop 策略及默认值 | turns/user_turn_strategies.py、各策略实现文件 |
| Smart Turn Overview | 解释 Smart Turn 为什么比纯 VAD 更自然 | audio/turn/smart_turn/、audio/turn/base_turn_analyzer.py |
| Speech to Text | 解释音频如何转录、何时得到 finalized transcript | services/stt_service.py 及各具体 STT 服务 |
5.13.1 官方文档说“通过 Aggregator 配置”,源码里到底在哪里生效?
官方文档里的示例通常从这里开始:
user_aggregator, assistant_aggregator = LLMContextAggregatorPair(
context,
user_params=LLMUserAggregatorParams(
vad_analyzer=SileroVADAnalyzer(),
user_turn_strategies=UserTurnStrategies(...),
),
)
这段配置在源码中的意义不是“把参数存起来”,而是把 turn detection 的两个核心入口挂进 user aggregator:
LLMUserAggregatorParams.vad_analyzer:决定是否启用本地 VAD,以及由谁产出VADUserStartedSpeakingFrame/VADUserStoppedSpeakingFrameLLMUserAggregatorParams.user_turn_strategies:决定谁来消费 VAD / transcript / audio 信号,并最终产出UserStartedSpeakingFrame/UserStoppedSpeakingFrame
也就是说,Aggregator 是装配点(assembly point),真正的轮次判断逻辑并不在 aggregator 内部,而是在 UserTurnController + strategies + analyzers 这条链上。
5.13.2 官方文档说“默认是 Smart Turn”,源码里的精确定义是什么?
公开文档里的说法是对的,但源码里更精确:
# src/pipecat/turns/user_turn_strategies.py
start = [VADUserTurnStartStrategy(), TranscriptionUserTurnStartStrategy()]
stop = [TurnAnalyzerUserTurnStopStrategy(turn_analyzer=LocalSmartTurnAnalyzerV3())]
这意味着默认配置不是单独一个 “Smart Turn 开关”,而是一组组合策略:
- Turn start:优先吃 VAD,必要时由 transcription 兜底
- Turn stop:固定走
TurnAnalyzerUserTurnStopStrategy - Turn analyzer:默认注入
LocalSmartTurnAnalyzerV3
所以官方文档里“Smart Turn is default”在代码层的准确翻译是: 默认 stop strategy = TurnAnalyzerUserTurnStopStrategy(LocalSmartTurnAnalyzerV3)。
5.13.3 官方文档强调 stop_secs=0.2,为什么源码层面这么敏感?
官方文档把 stop_secs=0.2 说成“通常不要改”,从源码看这个建议很合理,因为它不是孤立参数,而是会传导到多个模块:
- VAD 本身用它决定何时从
STOPPING转成QUIET TurnAnalyzerUserTurnStopStrategy用它做stt_timeout - stop_secs补偿SpeechTimeoutUserTurnStopStrategy也用同样的补偿逻辑BaseSmartTurn会把 VAD 的启动/停止延迟一起纳入音频窗口对齐
所以它不是一个单纯“更灵敏/更迟钝”的调参项,而是整个 turn timing 链路的基准时间常量。
5.13.4 官方文档把 STT 放到“下一节”,但源码里它和 turn detection 已经耦合了
文档叙事上,Speech Input & Turn Detection 之后才进入 Speech to Text;但源码里,这两部分其实已经互相依赖:
STTService.audio_passthrough=True默认把原始音频继续传给 turn analyzerSTTMetadataFrame把各家 STT 的 P99 TTFS 广播给 stop strategyTranscriptionFrame.finalized决定 turn stop 能否立刻触发,而不是继续等超时
所以从源码视角更准确的理解是: STT 不是 turn detection 的下游消费者,而是 turn stop 决策的一个输入信号源。
5.13.5 推荐的“文档 → 源码”阅读路径
如果你要继续往下深挖,推荐按这个顺序切换:
- 先读官方
Speech Input & Turn Detection,建立三层模型:VAD / turn start / turn stop - 再读
User Turn Strategies,把默认策略和可替换策略记清楚 - 接着读
Smart Turn Overview,理解为什么 stop 比 start 难得多 - 然后对照本仓库源码:
user_turn_strategies.py→user_turn_controller.py→turn_analyzer_user_turn_stop_strategy.py→stt_service.py - 最后再进入官方
Speech to Text页面,因为那时你已经知道 finalized transcript 为什么会直接影响 turn completion
这个顺序的好处是:你先理解“职责边界”,再看“事件编排”,最后看“服务延迟如何反向影响轮次结束”。
六、WebRTC Transports:实时通信传输层
Transports 是 Pipecat 的通信层——连接用户和 bot 的桥梁。它们负责接收和发送音频、视频和数据消息。本节聚焦 WebRTC 类型的 transport。
6.1 Transport 架构概览
6.1.1 类层次结构
BaseObject
└── BaseTransport # 抽象基类,定义 input()/output() 接口
├── DailyTransport # Daily WebRTC 实现
└── LiveKitTransport # LiveKit WebRTC 实现
FrameProcessor
├── BaseInputTransport # 输入基类,处理音频/视频输入、VAD(遗留)
│ ├── DailyInputTransport # Daily 输入实现
│ └── LiveKitInputTransport # LiveKit 输入实现
└── BaseOutputTransport # 输出基类,处理音频/视频输出、缓冲、混音
├── DailyOutputTransport # Daily 输出实现
└── LiveKitOutputTransport # LiveKit 输出实现
关键设计:Transport 拆分为 Input + Output
一个 Transport 不是单个 FrameProcessor,而是拆分为两个独立的处理器:
# base_transport.py:169-210
class BaseTransport(BaseObject):
@abstractmethod
def input(self) -> FrameProcessor:
"""返回输入帧处理器"""
pass
@abstractmethod
def output(self) -> FrameProcessor:
"""返回输出帧处理器"""
pass
在管道中的位置:
[InputTransport] → [STT] → [LLM] → [TTS] → [OutputTransport]
↑ 接收用户音频/视频 ↑ 发送 bot 音频/视频
为什么拆分?
- 职责分离:输入处理(VAD、音频过滤)和输出处理(缓冲、混音、计时)完全不同
- 管道灵活性:它们位于管道的首尾两端,中间可以插入任意数量的处理器
- 共享客户端:虽然是两个处理器,但共享一个底层客户端连接(
DailyTransportClient/LiveKitTransportClient)
6.1.2 TransportParams — 统一配置
# base_transport.py:27-167
class TransportParams(BaseModel):
# 音频输入
audio_in_enabled: bool = False
audio_in_sample_rate: Optional[int] = None # None = 使用 StartFrame 的值
audio_in_channels: int = 1
audio_in_filter: Optional[BaseAudioFilter] = None
audio_in_stream_on_start: bool = True # 是否立即开始接收音频
audio_in_passthrough: bool = True # 是否将音频帧推送下游
# 音频输出
audio_out_enabled: bool = False
audio_out_sample_rate: Optional[int] = None
audio_out_channels: int = 1
audio_out_bitrate: int = 96000
audio_out_10ms_chunks: int = 4 # 每次写入 40ms 音频
audio_out_mixer: Optional[BaseAudioMixer | Mapping] = None
audio_out_destinations: List[str] = [] # 多路输出
audio_out_end_silence_secs: int = 2 # EndFrame 后发送的静音时长
# 视频输入/输出
video_in_enabled: bool = False
video_out_enabled: bool = False
video_out_is_live: bool = False # 实时视频 vs 静态图片
video_out_width: int = 1024
video_out_height: int = 768
video_out_framerate: int = 30
video_out_codec: Optional[str] = None # VP8, H264, H265
6.2 BaseInputTransport — 输入处理基类
Source: src/pipecat/transports/base_input.py
BaseInputTransport 处理所有输入侧的共性逻辑:
6.2.1 音频输入管道
# base_input.py — 核心音频处理
async def push_audio_frame(self, frame: InputAudioRawFrame):
"""子类调用此方法将音频送入处理队列"""
if self._params.audio_in_enabled and not self._paused:
await self._audio_in_queue.put(frame)
async def _audio_task_handler(self):
"""独立任务:从队列取音频,过滤、VAD(遗留)、推送"""
while True:
frame = await asyncio.wait_for(
self._audio_in_queue.get(), timeout=0.5)
# 1. 音频过滤(如降噪)
if self._params.audio_in_filter:
frame.audio = await self._params.audio_in_filter.filter(frame.audio)
# 2. VAD 分析(遗留代码路径)
if self._params.vad_analyzer:
vad_state = await self._deprecated_handle_vad(frame, vad_state)
# 3. 推送音频帧下游
if self._params.audio_in_passthrough:
await self.push_frame(frame)
音频处理队列的作用: 将 transport 回调线程的音频数据桥接到 asyncio 事件循环。transport(如 Daily)可能在 C 层线程中产生音频回调,通过 asyncio.Queue 安全地传递到 Python 异步任务。
6.2.2 生命周期管理
# base_input.py
async def start(self, frame: StartFrame):
self._sample_rate = self._params.audio_in_sample_rate or frame.audio_in_sample_rate
if self._params.audio_in_filter:
await self._params.audio_in_filter.start(self._sample_rate)
async def set_transport_ready(self, frame: StartFrame):
"""transport 连接成功后调用,创建音频处理任务"""
self._create_audio_task()
async def stop(self, frame: EndFrame):
await self._cancel_audio_task()
if self._params.audio_in_filter:
await self._params.audio_in_filter.stop()
关键时序: start() 初始化参数 → set_transport_ready() 创建处理任务。中间是 transport 的连接时间(join room、WebRTC 协商等)。
6.3 BaseOutputTransport — 输出处理基类
Source: src/pipecat/transports/base_output.py
输出侧更复杂,需要处理音频缓冲、分块、混音、计时和 bot 说话状态。
6.3.1 音频分块
# base_output.py:109-121
async def start(self, frame: StartFrame):
self._sample_rate = self._params.audio_out_sample_rate or frame.audio_out_sample_rate
# 10ms × CHUNKS(默认 4 = 40ms)
audio_bytes_10ms = int(self._sample_rate / 100) * self._params.audio_out_channels * 2
self._audio_chunk_size = audio_bytes_10ms * self._params.audio_out_10ms_chunks
长音频帧被切分为 40ms 的小块发送。这对中断处理至关重要——如果 bot 正在播放一段 2 秒的 TTS 音频,用户开始说话时,最多只需要丢弃当前 40ms 的块,而不是整段音频。
6.3.2 MediaSender — 多路输出
每个输出目标(destination)有一个独立的 MediaSender,包含三个并发任务:
MediaSender (per destination)
├── Audio Task: 从音频队列取数据,分块、混音、计时、写入 transport
├── Video Task: 按目标帧率循环渲染图片/视频
└── Clock Task: PTS(Presentation Timestamp)驱动的帧调度
6.3.3 Bot Speaking 状态追踪
# base_output.py — 常量
BOT_VAD_STOP_SECS = 0.35 # 检测 bot 停止说话的静音阈值
BOT_VAD_STOP_FALLBACK_SECS = 3 # 后备超时
输出 transport 通过检测音频中的静音来判断 bot 是否停止说话:
- 收到
TTSAudioRawFrame→ bot 开始说话(BotStartedSpeakingFrame) - 连续 350ms 的静音音频 → bot 停止说话(
BotStoppedSpeakingFrame) - 在说话期间定期发送
BotSpeakingFrame
6.4 Daily WebRTC Transport
Source: src/pipecat/transports/daily/transport.py(~2960 行)
6.4.1 四层架构
DailyTransport (BaseTransport)
│ 管理 input/output 实例,注册事件处理器
│
├── DailyTransportClient (EventHandler)
│ 底层 Daily SDK 封装
│ 管理 CallClient、音视频轨道、回调处理
│
├── DailyInputTransport (BaseInputTransport)
│ 音频接收、参与者追踪、转录处理
│
└── DailyOutputTransport (BaseOutputTransport)
音频/视频发送、消息传递、SIP 操作
6.4.2 DailyTransportClient — SDK 封装
# daily/transport.py:494-558
class DailyTransportClient(EventHandler):
def __init__(self, room_url, token, bot_name, params, callbacks, transport_name):
if not DailyTransportClient._daily_initialized:
DailyTransportClient._daily_initialized = True
Daily.init() # 全局初始化一次
self._client: CallClient = CallClient(event_handler=self)
self._speaker: Optional[VirtualSpeakerDevice] = None # 虚拟扬声器
self._camera_track = None # 摄像头轨道
self._microphone_track = None # 麦克风轨道
self._custom_audio_tracks = {} # 自定义音频轨道
self._custom_video_tracks = {} # 自定义视频轨道
GIL 死锁解决方案:
Daily SDK 的回调发生在持有 GIL 的 C 线程中。如果在回调中调用 CallClient 方法并等待完成,会导致死锁。解决方案是使用独立的异步任务:
# daily/transport.py:569-571 (注释说明)
# We use separate tasks to execute callbacks (events, audio or video).
# daily-python holds the GIL when calling callbacks. So, if our callback
# handler makes a CallClient call and waits for its completion we will deadlock.
self._event_task = None
self._audio_task = None
self._video_task = None
6.4.3 音频输入:两种模式
模式 1:VirtualSpeaker(混合音频)
# daily/transport.py:651-673
async def read_next_audio_frame(self) -> Optional[InputAudioRawFrame]:
"""读取 20ms 的混合音频(所有参与者混合在一起)"""
num_frames = int(sample_rate / 100) * 2 # 20ms
future = self._get_event_loop().create_future()
self._speaker.read_frames(num_frames, completion=completion_callback(future))
audio = await future
if len(audio) > 0:
return InputAudioRawFrame(audio=audio, sample_rate=sample_rate, ...)
else:
await asyncio.sleep(0.01) # 没有参与者时的 busy wait
return None
模式 2:User Tracks(独立轨道,默认)
# daily/transport.py:364
class DailyParams(TransportParams):
audio_in_user_tracks: bool = True # 默认使用独立轨道
每个参与者的音频通过独立回调到达,携带 participant_id,生成 UserAudioRawFrame(包含 user_id 字段)。
6.4.4 连接生命周期
# daily/transport.py — DailyInputTransport
async def start(self, frame: StartFrame):
await super().start(frame)
if self._initialized:
return
self._initialized = True
# 1. 初始化客户端
await self._client.start(frame)
# 2. 加入房间
await self._client.join()
# 3. 标记 transport 就绪(创建音频处理任务)
await self.set_transport_ready(frame)
# 4. 开始音频流(如果配置为立即开始)
if self._params.audio_in_stream_on_start:
await self.start_audio_in_streaming()
StartFrame 到达
│
├── client.start() — 初始化 SDK、创建轨道
│
├── client.join() — 加入 Daily 房间
│ │
│ ├── WebRTC 信令协商
│ ├── ICE 候选交换
│ └── on_joined 回调 → 推送 BotConnectedFrame
│
├── set_transport_ready() — 创建音频处理任务
│
└── start_audio_in_streaming() — 开始接收参与者音频
│
├── (user_tracks=True) → 捕获每个参与者的独立轨道
└── (user_tracks=false) → 创建 VirtualSpeaker 读取任务
6.4.5 DailyTransport 事件系统
# daily/transport.py:2275-2365
class DailyTransport(BaseTransport):
def __init__(self, room_url, token, bot_name, params=None, ...):
# 创建回调映射
callbacks = DailyCallbacks(
on_joined=self._on_joined,
on_client_connected=self._on_client_connected,
on_participant_joined=self._on_participant_joined,
on_app_message=self._on_app_message,
# ... 25+ 事件
)
# 共享一个客户端
self._client = DailyTransportClient(room_url, token, bot_name, params, callbacks, ...)
# 注册用户可用的事件处理器
self._register_event_handler("on_joined")
self._register_event_handler("on_connected") # on_joined 别名
self._register_event_handler("on_first_participant_joined")
self._register_event_handler("on_client_connected") # on_participant_joined 别名
self._register_event_handler("on_app_message")
# ...
典型使用:
transport = DailyTransport(room_url, token, "Bot", params)
@transport.event_handler("on_first_participant_joined")
async def on_first_participant_joined(transport, participant):
await task.queue_frame(TTSSpeakFrame("Hello!"))
@transport.event_handler("on_participant_left")
async def on_participant_left(transport, participant, reason):
await task.queue_frame(EndFrame())
6.4.6 Daily 特有功能
| 功能 | 帧/方法 | 说明 |
|---|---|---|
| SIP 转接 | DailySIPTransferFrame | 排队的 SIP TRANSFER,等当前音频播完再执行 |
| SIP REFER | DailySIPReferFrame | 排队的 SIP REFER |
| 转录 | transcription_enabled + DailyTranscriptionSettings | 内置 Deepgram 转录 |
| 录制 | start_recording() / stop_recording() | 房间录制 |
| 拨入/拨出 | DailyDialinSettings, start_dialout() | PSTN 集成 |
| 多轨道 | custom_audio_track_params, custom_video_track_params | 自定义音视频轨道 |
| WebRTC VAD | WebRTCVADAnalyzer | Daily 原生 VAD 实现 |
6.5 LiveKit WebRTC Transport
Source: src/pipecat/transports/livekit/transport.py(~1250 行)
6.5.1 架构
LiveKitTransport (BaseTransport)
│
├── LiveKitTransportClient
│ 管理 rtc.Room、音视频轨道订阅
│
├── LiveKitInputTransport (BaseInputTransport)
│ 音频/视频接收、重采样、格式转换
│
└── LiveKitOutputTransport (BaseOutputTransport)
音频发布、数据消息、DTMF
6.5.2 LiveKitTransportClient
# livekit/transport.py:174
class LiveKitTransportClient:
def __init__(self, ...):
self._room = rtc.Room()
self._audio_source: Optional[rtc.AudioSource] = None
# 异步队列桥接 LiveKit 回调和 Pipecat 处理
self._audio_queue: asyncio.Queue = asyncio.Queue()
self._video_queue: asyncio.Queue = asyncio.Queue()
重试连接:
# LiveKit 使用 tenacity 重试
@retry(stop=stop_after_attempt(3), wait=wait_exponential(multiplier=1, min=1, max=10))
async def connect(self, ...):
await self._room.connect(url, token)
6.5.3 音频流处理
LiveKit 使用异步生成器模式接收音频:
# livekit/transport.py — LiveKitInputTransport
async def _audio_in_task_handler(self):
"""从所有参与者接收音频"""
async for audio_event, participant_id in self._client.get_next_audio_frame():
# LiveKit 返回的音频可能需要重采样
resampled = resample_audio(audio_event.frame, self.sample_rate)
frame = UserAudioRawFrame(
user_id=participant_id,
audio=resampled,
sample_rate=self.sample_rate,
num_channels=1,
)
await self.push_audio_frame(frame)
6.5.4 音频输出
# livekit/transport.py — LiveKitOutputTransport
async def write_audio_frame(self, frame: OutputAudioRawFrame):
"""将音频帧发布到 LiveKit 房间"""
audio_frame = rtc.AudioFrame(
data=frame.audio,
sample_rate=self.sample_rate,
num_channels=frame.num_channels,
samples_per_channel=len(frame.audio) // (frame.num_channels * 2),
)
await self._audio_source.capture_frame(audio_frame)
6.5.5 Daily vs LiveKit 对比
| 特性 | Daily | LiveKit |
|---|---|---|
| SDK | daily-python(C 扩展 + GIL) | livekit-rtc(纯 Python async) |
| 音频读取 | VirtualSpeaker.read_frames() | rtc.AudioStream 异步迭代 |
| 音频写入 | CallClient.send_app_message() | AudioSource.capture_frame() |
| 多轨道 | 原生支持(CustomAudioTrack/CustomVideoTrack) | 单轨道 |
| 转录 | 内置 Deepgram 集成 | 无内置,需外部 STT |
| SIP/PSTN | 原生拨入/拨出 | 无内置 |
| 录制 | 原生支持 | 无内置 |
| DTMF | 原生支持 | RFC 4733 数据通道 |
| 重试 | 手动 join | tenacity 自动重试 |
| 代码量 | ~2960 行 | ~1250 行 |
| GIL 问题 | 需要独立任务避免死锁 | 无(纯 async) |
6.6 SmallWebRTC Transport — 轻量级自托管 WebRTC
Source: src/pipecat/transports/smallwebrtc/
Daily 和 LiveKit 都是 SFU(Selective Forwarding Unit) 方案——需要云端中转服务器。SmallWebRTC 则完全不同:它是一个基于 aiortc 的 纯 Python P2P WebRTC 实现,允许你在自己的服务器上直接与浏览器建立点对点连接,无需任何第三方 SFU 服务。
6.6.1 与 SFU 方案的根本差异
SFU 方案(Daily / LiveKit):
浏览器 ←──WebRTC──→ [SFU 服务器] ←──WebRTC──→ Pipecat Bot
SmallWebRTC(P2P):
浏览器 ←──WebRTC──→ Pipecat Bot(同一进程内的 aiortc)
| 维度 | SFU(Daily/LiveKit) | SmallWebRTC(P2P) |
|---|---|---|
| 依赖 | 云端 SFU 服务 | 仅 aiortc(纯 Python) |
| 信令 | SDK 内置 | 需自行实现(提供 FastAPI handler) |
| NAT 穿透 | SFU 服务器天然解决 | 需配置 ICE/TURN 服务器 |
| 扩展性 | 多方通话、录制、转码 | 仅 1:1 连接(或少量多连接) |
| 部署 | 需要 API key | 完全自托管 |
| 成本 | 按用量付费 | 零运行成本(自托管) |
| 适用场景 | 生产环境、多方通话 | 本地开发、嵌入式设备、隐私敏感场景 |
6.6.2 三层架构
SmallWebRTCTransport (BaseTransport)
│ 顶层入口,注册事件,创建 input/output
│
├── SmallWebRTCClient
│ 中间层,管理 RawAudioTrack/RawVideoTrack,读写音视频
│
├── SmallWebRTCConnection (BaseObject)
│ 底层,封装 aiortc 的 RTCPeerConnection,管理信令和轨道
│
├── SmallWebRTCInputTransport (BaseInputTransport)
│ 音频/视频接收
│
└── SmallWebRTCOutputTransport (BaseOutputTransport)
音频/视频发送
外部组件:
SmallWebRTCRequestHandler ← 处理 HTTP 信令请求(SDP offer/answer)
6.6.3 SmallWebRTCConnection — WebRTC 信令与连接管理
Source: src/pipecat/transports/smallwebrtc/connection.py
这是整个 SmallWebRTC 的核心——封装了 aiortc 的 RTCPeerConnection。
连接建立流程:
浏览器 服务器(Pipecat)
│ │
│──── SDP Offer ──────────→│ SmallWebRTCRequestHandler.handle_web_request()
│ │ ├── SmallWebRTCConnection()
│ │ ├── connection.initialize(sdp, type)
│ │ │ ├── pc.setRemoteDescription(offer)
│ │ │ ├── force_transceivers_to_send_recv()
│ │ │ ├── pc.createAnswer()
│ │ │ └── pc.setLocalDescription(answer)
│ │ └── webrtc_connection_callback(connection)
│←── SDP Answer ───────────│ → 创建 SmallWebRTCTransport
│ │
│──── ICE Candidates ─────→│ handle_patch_request()
│←── ICE Candidates ───────│ → pc.addIceCandidate()
│ │
│════ WebRTC Connected ════│ connectionstatechange → "connected"
│ │ → _handle_client_connected()
│ │ → ClientConnectedFrame
│ │
│── Data Channel Open ────→│ on("datachannel") → _flush_message_queue()
│── ping (keepalive) ─────→│ 更新 _last_received_time
│── JSON messages ────────→│ on("message") → event_handler("app-message")
信令不是 WebRTC 的一部分——WebRTC 标准只定义了媒体传输,不定义如何交换 SDP。SmallWebRTC 通过 HTTP 端点实现信令,由 SmallWebRTCRequestHandler 处理。
Transceiver 管理:
# connection.py — 固定的 transceiver 布局
AUDIO_TRANSCEIVER_INDEX = 0 # 第一个 transceiver = 音频
VIDEO_TRANSCEIVER_INDEX = 1 # 第二个 = 摄像头视频
SCREEN_VIDEO_TRANSCEIVER_INDEX = 2 # 第三个 = 屏幕共享
aiortc 不完全遵守 SDP 中的 sendrecv 指令,需要强制设置:
# connection.py:436-444
def force_transceivers_to_send_recv(self):
transceivers = self._pc.getTransceivers()
for i, transceiver in enumerate(transceivers):
if i < 2: # 音频和视频:双向
transceiver.direction = "sendrecv"
else: # 屏幕共享:仅接收
transceiver.direction = "recvonly"
连接状态检测——aiortc 的不足与变通:
aiortc 不支持 disconnected 状态(只有 connected/failed/closed)。SmallWebRTC 通过 Data Channel ping 心跳 自行检测断连:
# connection.py:626-642
def is_connected(self) -> bool:
if not self._connect_invoked:
return False
if self._last_received_time is None:
# 从未收到消息,信任 aiortc 的状态
return self._pc.connectionState == "connected"
# 3 秒内收到过 ping → 连接正常
return (time.time() - self._last_received_time) < 3
浏览器端定期发送 "ping" 消息,服务器通过 _last_received_time 追踪。超过 3 秒没收到 ping = 断连。
连接超时保护:
# connection.py:534-551
def _monitoring_connecting_state(self):
"""connecting 状态超过 60 秒 → 自动关闭"""
async def timeout_handler():
await asyncio.sleep(self.connection_timeout_secs) # 默认 60s
logger.warning("Timeout establishing the connection. Closing.")
await self._close()
self._connecting_timeout_task = asyncio.create_task(timeout_handler())
Data Channel 超时:
# connection.py:565-589
def _start_data_channel_timeout(self):
"""连接成功后 10 秒内 data channel 仍未打开 → 禁用消息队列"""
async def timeout_handler():
await asyncio.sleep(DATA_CHANNEL_TIMEOUT_SECS) # 10s
if not self._data_channel or self._data_channel.readyState != "open":
self._outgoing_messages_queue.clear()
self._data_channel_enabled = False # 后续消息直接丢弃
self._data_channel_timeout_task = asyncio.create_task(timeout_handler())
6.6.4 SmallWebRTCTrack — 轨道包装器
# connection.py:96-199
class SmallWebRTCTrack:
def __init__(self, receiver):
self._receiver = receiver
self._receiver._enabled = False # 默认不消费,防止内存增长
self._track = receiver.track
self._enabled = True
self._idle_timeout = 2.0 # 2 秒无人读取 → 停止接收
关键设计:延迟消费 + 闲置回收
aiortc 的 RemoteStreamTrack 会不断将收到的帧放入内部队列。如果没有消费者读取,队列会无限增长导致内存泄漏。SmallWebRTCTrack 的解决方案:
- 默认禁用接收:
receiver._enabled = False,帧不入队列 - 按需启用:
recv()被调用时才启用,记录最后读取时间 - 闲置看门狗:如果 2 秒没有
recv()调用,自动禁用接收并丢弃积压帧
# connection.py:148-178
async def recv(self) -> Optional[Frame]:
self._receiver._enabled = True # 开始接收
self._last_recv_time = time.time()
if not self._idle_task or self._idle_task.done():
self._idle_task = asyncio.create_task(self._idle_watcher())
if not self._enabled and self._track.kind == "video":
return None # 视频轨道可被禁用
return await self._track.recv()
async def _idle_watcher(self):
"""超过 idle_timeout 没读取 → 禁用接收,清空积压"""
while self._receiver._enabled:
await asyncio.sleep(self._idle_timeout)
if time.time() - self._last_recv_time >= self._idle_timeout:
await self.discard_old_frames() # 清空 aiortc 内部队列
self._receiver._enabled = False
6.6.5 RawAudioTrack / RawVideoTrack — 输出轨道
与 Daily/LiveKit 不同,SmallWebRTC 需要自己实现 WebRTC 的媒体轨道接口把手里的原始 PCM 音频数据,适配成 aiortc WebRTC 音轨所需要的"按帧拉取"接口。
这是因为aiortc 的音频轨道采用拉模式——底层编码器会不断调用 recv() 来索要下一帧音频。但你的数据来源不同,一次性给你一大段 bytes。两边节奏不同,需要一个中间层来适配。 RawAudioTrack — 音频输出:
# transport.py:75-150
class RawAudioTrack(AudioStreamTrack):
"""继承 aiortc 的 AudioStreamTrack,实现 recv() 接口"""
def __init__(self, sample_rate):
self._samples_per_10ms = sample_rate * 10 // 1000
self._bytes_per_10ms = self._samples_per_10ms * 2 # 16-bit PCM
self._chunk_queue = deque() # (bytes, future) 队列
def add_audio_bytes(self, audio_bytes: bytes):
"""将音频数据切成 10ms 块放入队列"""
future = asyncio.get_running_loop().create_future()
for i in range(0, len(audio_bytes), self._bytes_per_10ms):
chunk = audio_bytes[i : i + self._bytes_per_10ms]
# 只有最后一块携带 future(标记整段数据消费完毕)
fut = future if i + self._bytes_per_10ms >= len(audio_bytes) else None
self._chunk_queue.append((chunk, fut))
return future
async def recv(self):
"""aiortc 调用此方法获取下一帧音频"""
# 时钟同步:按照 PTS 计算应该等待的时间
if self._timestamp > 0:
wait = self._start + (self._timestamp / self._sample_rate) - time.time()
if wait > 0:
await asyncio.sleep(wait)
if self._chunk_queue:
chunk, future = self._chunk_queue.popleft()
if future and not future.done():
future.set_result(True) # 通知调用者数据已消费
else:
chunk = bytes(self._bytes_per_10ms) # 没数据 → 发静音
# 转换为 aiortc 需要的 AudioFrame 格式
samples = np.frombuffer(chunk, dtype=np.int16)
frame = AudioFrame.from_ndarray(samples[None, :], layout="mono")
frame.sample_rate = self._sample_rate
frame.pts = self._timestamp
self._timestamp += self._samples_per_10ms
return frame
与 Daily/LiveKit 的对比:
- Daily: 调用
CallClient的 C API 写入音频,SDK 内部处理计时 - LiveKit: 调用
AudioSource.capture_frame()推送,SDK 内部处理 - SmallWebRTC: 必须自己实现
recv()拉模式,自己处理时钟同步和静音填充
RawVideoTrack 类似,但使用 asyncio.Queue 而非 deque,因为视频帧率由 aiortc 的 next_timestamp() 控制。
6.6.6 SmallWebRTCClient — 音视频桥接
# transport.py:200-543
class SmallWebRTCClient:
def __init__(self, webrtc_connection, callbacks):
self._webrtc_connection = webrtc_connection
self._audio_output_track = None # RawAudioTrack
self._video_output_track = None # RawVideoTrack
self._audio_input_track = None # SmallWebRTCTrack
self._video_input_track = None # SmallWebRTCTrack
self._screen_video_track = None # SmallWebRTCTrack
客户端连接时的轨道替换:
# transport.py:477-496
async def _handle_client_connected(self):
# 获取输入轨道(从远端接收)
self._audio_input_track = self._webrtc_connection.audio_input_track()
self._video_input_track = self._webrtc_connection.video_input_track()
self._screen_video_track = self._webrtc_connection.screen_video_input_track()
# 创建输出轨道并替换到 transceiver 的 sender 中
if self._params.audio_out_enabled:
self._audio_output_track = RawAudioTrack(sample_rate=self._out_sample_rate)
self._webrtc_connection.replace_audio_track(self._audio_output_track)
if self._params.video_out_enabled:
self._video_output_track = RawVideoTrack(width=..., height=...)
self._webrtc_connection.replace_video_track(self._video_output_track)
音频读取——异步生成器模式:
# transport.py:346-401
async def read_audio_frame(self):
"""从 WebRTC 连接读取音频帧的异步生成器"""
while True:
if self._audio_input_track is None:
await asyncio.sleep(0.01)
continue
frame = await asyncio.wait_for(self._audio_input_track.recv(), timeout=2.0)
# 重采样到目标采样率
frames_to_process = (
self._audio_in_resampler.resample(frame)
if frame.sample_rate != self._in_sample_rate
else [frame]
)
for processed_frame in frames_to_process:
pcm_array = processed_frame.to_ndarray().astype(np.int16)
yield InputAudioRawFrame(
audio=pcm_array.tobytes(),
sample_rate=self._in_sample_rate,
num_channels=self._audio_in_channels,
)
视频读取——格式转换:
# transport.py:207-212
FORMAT_CONVERSIONS = {
"yuv420p": cv2.COLOR_YUV2RGB_I420,
"yuvj420p": cv2.COLOR_YUV2RGB_I420,
"nv12": cv2.COLOR_YUV2RGB_NV12,
"gray": cv2.COLOR_GRAY2RGB,
}
WebRTC 视频通常是 YUV 格式,需要用 OpenCV 转换为 RGB。
6.6.7 SmallWebRTCRequestHandler — HTTP 信令处理
Source: src/pipecat/transports/smallwebrtc/request_handler.py
由于 WebRTC 标准不定义信令,SmallWebRTC 提供了一个 HTTP 请求处理器来管理 SDP 交换和 ICE 候选传递。
两种连接模式:
# request_handler.py:78-82
class ConnectionMode(Enum):
SINGLE = "single" # 只允许一个活跃连接(1:1 bot)
MULTIPLE = "multiple" # 允许多个并发连接
请求处理流程:
# request_handler.py:159-238
async def handle_web_request(self, request, webrtc_connection_callback):
pc_id = request.pc_id
# 1. 检查连接模式约束
self._check_single_connection_constraints(pc_id)
existing_connection = self._pcs_map.get(pc_id) if pc_id else None
if existing_connection:
# 2a. 已有连接 → 重新协商
await pipecat_connection.renegotiate(sdp, type, restart_pc)
else:
# 2b. 新连接 → 创建 SmallWebRTCConnection
pipecat_connection = SmallWebRTCConnection(ice_servers=self._ice_servers)
await pipecat_connection.initialize(sdp=request.sdp, type=request.type)
# 注册断连清理
@pipecat_connection.event_handler("closed")
async def handle_disconnected(conn):
self._pcs_map.pop(conn.pc_id, None)
# 3. 回调创建 transport 和 pipeline
await webrtc_connection_callback(pipecat_connection)
# 4. 返回 SDP Answer
answer = pipecat_connection.get_answer()
self._pcs_map[answer["pc_id"]] = pipecat_connection
return answer
ICE 候选补丁:
# request_handler.py:240-251
async def handle_patch_request(self, request: SmallWebRTCPatchRequest):
"""处理后续的 ICE 候选补丁(Trickle ICE)"""
peer_connection = self._pcs_map.get(request.pc_id)
for c in request.candidates:
candidate = candidate_from_sdp(c.candidate)
candidate.sdpMid = c.sdp_mid
await peer_connection.add_ice_candidate(candidate)
6.6.8 SmallWebRTCTransport — 顶层入口
# transport.py:863-998
class SmallWebRTCTransport(BaseTransport):
def __init__(self, webrtc_connection, params, ...):
self._client = SmallWebRTCClient(webrtc_connection, callbacks)
def input(self) -> SmallWebRTCInputTransport:
if not self._input:
self._input = SmallWebRTCInputTransport(self._client, self._params, ...)
return self._input
def output(self) -> SmallWebRTCOutputTransport:
if not self._output:
self._output = SmallWebRTCOutputTransport(self._client, self._params, ...)
return self._output
事件系统极简: 只有 3 个事件(对比 Daily 的 25+ 个):
self._register_event_handler("on_app_message")
self._register_event_handler("on_client_connected")
self._register_event_handler("on_client_disconnected")
连接时推送 ClientConnectedFrame:
# transport.py:965-969
async def _on_client_connected(self, webrtc_connection):
await self._call_event_handler("on_client_connected", webrtc_connection)
if self._input:
await self._input.push_frame(ClientConnectedFrame())
注意:SmallWebRTC 不推送 BotConnectedFrame(没有 SFU 房间的概念,bot 就是服务器本身)。
6.6.9 回调函数机制深度解析
SmallWebRTCTransport 的回调机制是一个 四层事件传播链,将底层 aiortc 的原生事件逐层抽象,最终暴露给用户代码。这是理解整个 SmallWebRTC 架构的核心。
第一层:aiortc → SmallWebRTCConnection(原生事件 → BaseObject 事件)
aiortc 的 RTCPeerConnection 使用 pyee(Python EventEmitter)风格的 @pc.on("event") 装饰器注册回调。SmallWebRTCConnection._setup_listeners() 在此层完成事件协议转换:
# connection.py:297-356 — _setup_listeners()
def _setup_listeners(self):
"""将 aiortc 原生事件桥接到 BaseObject 事件系统"""
@self._pc.on("connectionstatechange")
async def on_connectionstatechange():
await self._handle_new_connection_state()
@self._pc.on("track")
async def on_track(track):
await self._call_event_handler("track-started", track)
@track.on("ended")
async def on_ended():
await self._call_event_handler("track-ended", track)
@self._pc.on("datachannel")
def on_datachannel(channel):
self._data_channel = channel
@channel.on("message")
async def on_message(message):
if isinstance(message, str) and message.startswith("ping"):
self._last_received_time = time.time() # 心跳检测
else:
json_message = json.loads(message)
await self._call_event_handler("app-message", json_message)
关键转换点——_handle_new_connection_state():
# connection.py:603-621
async def _handle_new_connection_state(self):
state = self._pc.connectionState # "connecting" | "connected" | "failed" | ...
if state == "connecting":
self._monitoring_connecting_state() # 启动 60s 超时监控
else:
self._cancel_monitoring_connecting_state() # 取消超时
if state == "connected" and not self._connect_invoked:
return # 管道还没准备好,暂不触发事件
# ★ 核心:将 aiortc 的连接状态字符串直接作为事件名触发
await self._call_event_handler(state)
这里的设计巧妙之处在于 SmallWebRTCConnection.__init__() 中预注册了所有可能的状态字符串作为事件名:
# connection.py:248-258
self._register_event_handler("app-message")
self._register_event_handler("track-started")
self._register_event_handler("track-ended")
self._register_event_handler("connecting")
self._register_event_handler("connected") # ← 状态字符串 == 事件名
self._register_event_handler("disconnected")
self._register_event_handler("closed")
self._register_event_handler("failed")
self._register_event_handler("new")
这意味着 aiortc 的 connectionState 属性值可以直接用作 _call_event_handler() 的参数,无需任何映射表。
_connect_invoked 门控: 注意 _handle_new_connection_state() 中的守卫条件。WebRTC 连接可能在 Pipeline 准备好之前就已经 “connected”(SDP 交换完成即建立连接),但此时 SmallWebRTCClient 和 SmallWebRTCTransport 还没完成初始化。_connect_invoked 确保 “connected” 事件只在 connect() 方法被调用后才触发:
# connection.py:383-388
async def connect(self):
self._connect_invoked = True
if self.is_connected():
# 如果已经连接了,手动重新触发 connected 事件
await self._call_event_handler("connected")
第二层:SmallWebRTCConnection → SmallWebRTCClient(BaseObject 装饰器注册)
SmallWebRTCClient.__init__() 通过 BaseObject.event_handler() 装饰器在 connection 上注册回调:
# transport.py:240-257 — SmallWebRTCClient.__init__()
@self._webrtc_connection.event_handler("connected")
async def on_connected(connection: SmallWebRTCConnection):
logger.debug("Peer connection established.")
await self._handle_client_connected()
@self._webrtc_connection.event_handler("disconnected")
async def on_disconnected(connection: SmallWebRTCConnection):
await self._handle_peer_disconnected()
@self._webrtc_connection.event_handler("closed")
async def on_closed(connection: SmallWebRTCConnection):
await self._handle_client_closed()
@self._webrtc_connection.event_handler("app-message")
async def on_app_message(connection: SmallWebRTCConnection, message: Any):
await self._handle_app_message(message, connection.pc_id)
BaseObject 事件系统工作原理:
# base_object.py:102-116 — event_handler 装饰器
def event_handler(self, event_name: str):
def decorator(handler):
self.add_event_handler(event_name, handler) # 追加到 handlers 列表
return handler
return decorator
# base_object.py:145-174 — _call_event_handler
async def _call_event_handler(self, event_name: str, *args, **kwargs):
event_handler = self._event_handlers[event_name]
for handler in event_handler.handlers:
if event_handler.is_sync:
await self._run_handler(event_handler.name, handler, *args, **kwargs)
else:
# ★ 默认行为:每个 handler 创建一个独立的 asyncio.Task
task = asyncio.create_task(
self._run_handler(event_handler.name, handler, *args, **kwargs)
)
self._event_tasks.add((event_name, task))
# base_object.py:176-189 — _run_handler
async def _run_handler(self, event_name, handler, *args, **kwargs):
if inspect.iscoroutinefunction(handler):
await handler(self, *args, **kwargs) # ★ self 被注入为第一个参数
else:
handler(self, *args, **kwargs)
self 注入机制: _run_handler() 调用 handler(self, *args, **kwargs) 时,self 是 发起事件的对象(即 SmallWebRTCConnection 实例),而不是注册 handler 的对象。所以 on_connected(connection) 的 connection 参数实际上是 SmallWebRTCConnection 实例。
事件执行模式: SmallWebRTCConnection 注册事件时没有传 sync=True,所以使用默认的异步模式——每个 handler 在独立的 asyncio.Task 中执行。这意味着事件触发后不会等待 handler 完成就返回。
第三层:SmallWebRTCClient → SmallWebRTCTransport(Pydantic Callbacks 桥接)
这是最有趣的一层。SmallWebRTC 没有 使用 BaseObject 事件系统在 Client 和 Transport 之间传递事件,而是使用了一个 Pydantic BaseModel 作为类型安全的回调容器:
# transport.py:61-72 — SmallWebRTCCallbacks
class SmallWebRTCCallbacks(BaseModel):
"""Callback handlers for SmallWebRTC events."""
on_app_message: Callable[[Any, str], Awaitable[None]]
on_client_connected: Callable[[SmallWebRTCConnection], Awaitable[None]]
on_client_disconnected: Callable[[SmallWebRTCConnection], Awaitable[None]]
SmallWebRTCTransport.__init__() 创建这个回调容器,将自己的方法绑定进去:
# transport.py:900-906
self._callbacks = SmallWebRTCCallbacks(
on_app_message=self._on_app_message,
on_client_connected=self._on_client_connected,
on_client_disconnected=self._on_client_disconnected,
)
# 回调容器传给 Client
self._client = SmallWebRTCClient(webrtc_connection, self._callbacks)
Client 内部通过调用 self._callbacks.xxx() 传递事件:
# transport.py:477-496 — SmallWebRTCClient._handle_client_connected()
async def _handle_client_connected(self):
# ... 获取输入轨道、创建输出轨道 ...
self._audio_input_track = self._webrtc_connection.audio_input_track()
if self._params.audio_out_enabled:
self._audio_output_track = RawAudioTrack(sample_rate=self._out_sample_rate)
self._webrtc_connection.replace_audio_track(self._audio_output_track)
# ★ 通过 Pydantic Callbacks 调用 Transport 的方法
await self._callbacks.on_client_connected(self._webrtc_connection)
# transport.py:506-517 — _handle_client_closed()
async def _handle_client_closed(self):
# ... 清理轨道引用 ...
if not self._closing: # 只有客户端主动断开才触发
await self._callbacks.on_client_disconnected(self._webrtc_connection)
为什么用 Pydantic 而不是 BaseObject 事件?
- 类型安全:
SmallWebRTCClient不继承BaseObject,它是一个纯业务类。Pydantic 的Callable类型注解提供了编译期的类型检查 - 同步调用:Pydantic Callbacks 是直接的
await调用,不像 BaseObject 事件那样默认创建独立 Task。这保证了 Client → Transport 的事件传播是同步的——Transport 的 handler 完成后 Client 才继续 - 明确的契约:三个回调字段精确定义了 Client 与 Transport 之间的通信接口,没有运行时注册的灵活性但也没有注册遗漏的风险
第四层:SmallWebRTCTransport → 用户代码(BaseObject 事件系统)
Transport 收到 Client 的回调后,通过 BaseObject 事件系统暴露给用户代码:
# transport.py:911-915 — 注册用户可用的事件
self._register_event_handler("on_app_message")
self._register_event_handler("on_client_connected")
self._register_event_handler("on_client_disconnected")
# transport.py:965-973 — Transport 内部 handler(被 Pydantic Callback 调用)
async def _on_client_connected(self, webrtc_connection):
# ★ 先触发用户注册的事件 handler
await self._call_event_handler("on_client_connected", webrtc_connection)
# ★ 然后推送框架级别的 Frame
if self._input:
await self._input.push_frame(ClientConnectedFrame())
async def _on_client_disconnected(self, webrtc_connection):
await self._call_event_handler("on_client_disconnected", webrtc_connection)
async def _on_app_message(self, message: Any, sender: str):
if self._input:
await self._input.push_app_message(message)
await self._call_event_handler("on_app_message", message, sender)
用户通过 BaseObject.event_handler() 装饰器注册处理函数:
# 用户代码
@transport.event_handler("on_client_connected")
async def on_client_connected(transport, client):
logger.info(f"Client connected: {client.pc_id}")
await task.queue_frames([...])
注意此处 transport 参数是由 _run_handler(self, ...) 注入的 self(即 SmallWebRTCTransport 实例),client 是传递过来的 webrtc_connection。
完整调用链追踪
以 “客户端连接” 事件为例,追踪完整调用链:
[aiortc RTCPeerConnection]
│ connectionstatechange 事件(pyee EventEmitter)
│
▼
[SmallWebRTCConnection._setup_listeners()]
│ @self._pc.on("connectionstatechange")
│ → _handle_new_connection_state()
│ → self._call_event_handler("connected") ← BaseObject 事件
│
▼
[SmallWebRTCClient.__init__() 中注册的 handler]
│ @self._webrtc_connection.event_handler("connected")
│ async def on_connected(connection):
│ → self._handle_client_connected()
│ → 获取输入轨道、创建输出轨道
│ → self._callbacks.on_client_connected() ← Pydantic Callback(直接 await)
│
▼
[SmallWebRTCTransport._on_client_connected()]
│ → self._call_event_handler("on_client_connected", connection) ← BaseObject 事件
│ → self._input.push_frame(ClientConnectedFrame()) ← 推入管道
│
▼
[用户代码]
│ @transport.event_handler("on_client_connected")
│ async def on_client_connected(transport, client):
│ → 用户逻辑
│
▼
[Pipeline]
│ ClientConnectedFrame 进入管道
│ → UserTurnProcessor, LLMContextAggregator 等处理器响应
三种事件传递机制对比
| 特性 | pyee(aiortc) | BaseObject 事件 | Pydantic Callbacks |
|---|---|---|---|
| 使用位置 | 第一层 | 第二/四层 | 第三层 |
| 注册方式 | @pc.on("event") | @obj.event_handler("event") | 构造函数参数 |
| 多 handler | 支持 | 支持(列表追加) | 不支持(1:1 绑定) |
| 执行模式 | 同步 emit() | 默认异步 Task | 直接 await |
self 注入 | 无 | 注入事件源对象 | 无(绑定方法自带 self) |
| 类型安全 | 无 | 无(字符串事件名) | 有(Callable 类型注解) |
| 用途 | 底层协议事件 | 框架级事件暴露 | 内部组件通信 |
设计要点
P1: 事件协议不统一是有意为之。 三种机制各有适用场景:pyee 是 aiortc 强制的,BaseObject 事件是 Pipecat 框架标准(支持多 handler、异步 Task),Pydantic Callbacks 是 Client-Transport 内部的类型安全同步通道。
P2: 异步 Task 创建的时序影响。 BaseObject 事件默认创建 asyncio.Task,这意味着第二层(Connection → Client)的 handler 调用是非阻塞的。当 _handle_new_connection_state() 调用 _call_event_handler("connected") 后,它立即返回,不等 Client 完成轨道设置。但第三层(Client → Transport)是直接 await,保证了轨道设置完成后才触发用户事件。
P3: _closing 标志防止双向触发。 SmallWebRTCClient._handle_client_closed() 检查 self._closing:如果是我们主动断开(disconnect() 设置 _closing=True),则不触发 on_client_disconnected 回调,避免用户代码在主动关闭时收到多余的断连通知。
6.6.10 连接生命周期(SmallWebRTC)
HTTP Request(SDP Offer 到达)
│
├── RequestHandler.handle_web_request()
│ │
│ ├── SmallWebRTCConnection.initialize(sdp)
│ │ ├── setRemoteDescription(offer)
│ │ ├── force_transceivers_to_send_recv()
│ │ ├── createAnswer()
│ │ └── setLocalDescription(answer)
│ │
│ └── webrtc_connection_callback()
│ → 创建 SmallWebRTCTransport + Pipeline + Task
│
├── HTTP Response(SDP Answer)→ 浏览器
│
├── ICE Candidates 交换(HTTP PATCH)
│
├── WebRTC 连接建立
│ │
│ ├── connectionstatechange → "connected"
│ │ ├── _cancel_monitoring_connecting_state()
│ │ └── _start_data_channel_timeout()
│ │
│ └── SmallWebRTCClient._handle_client_connected()
│ ├── 获取输入轨道(audio_input_track, video_input_track)
│ ├── 创建输出轨道(RawAudioTrack, RawVideoTrack)
│ ├── replace_audio_track() / replace_video_track()
│ └── callbacks.on_client_connected()
│ → SmallWebRTCTransport._on_client_connected()
│ → push_frame(ClientConnectedFrame)
│
Pipeline StartFrame
│
├── SmallWebRTCInputTransport.start()
│ ├── client.setup(params, frame)
│ ├── client.connect() ← 如果已连接则直接触发 connected
│ ├── set_transport_ready()
│ └── create_task(_receive_audio)
│ └── async for frame in client.read_audio_frame(): ...
│
... 对话进行 ...
│
├── EndFrame → InputTransport.stop()
│ ├── cancel audio/video tasks
│ └── client.disconnect()
│ ├── send_app_message(PeerLeftMessage)
│ └── pc.close()
│
└── 或者:客户端断连(ping 超时 3 秒)
└── _handle_client_closed()
→ callbacks.on_client_disconnected()
6.6.11 三种 WebRTC Transport 完整对比
| 特性 | Daily | LiveKit | SmallWebRTC |
|---|---|---|---|
| 架构 | SFU(云端中转) | SFU(云端中转) | P2P(直连) |
| 底层 SDK | daily-python(C 扩展) | livekit-rtc(Python) | aiortc(纯 Python) |
| 信令 | SDK 内置 | SDK 内置 | HTTP API(自行实现) |
| 连接模型 | 加入房间 | 加入房间 | 接收 SDP offer |
| BotConnectedFrame | 有(join 回调) | 有(connect 回调) | 无(无房间概念) |
| 音频输入 | VirtualSpeaker / UserTracks | AudioStream 异步迭代 | AudioStreamTrack.recv() |
| 音频输出 | SDK API 推送 | AudioSource.capture | RawAudioTrack.recv()(拉模式) |
| 视频格式转换 | SDK 内部处理 | protobuf → RGB | YUV → RGB(OpenCV) |
| 断连检测 | SDK 回调 | SDK 回调 | ping 心跳(3s 超时) |
| 多方通话 | 原生支持 | 原生支持 | SINGLE/MULTIPLE 模式 |
| 转录 | 内置 Deepgram | 无 | 无 |
| SIP/PSTN | 原生 | 无 | 无 |
| 录制 | 原生 | 无 | 无 |
| DTMF | 原生 | RFC 4733 | 无 |
| ESP32 | 不支持 | 不支持 | SDP munging 支持 |
| GIL 问题 | 需要 workaround | 无 | 无 |
| 事件数量 | 25+ | ~5 | 3 |
| 代码量 | ~2960 行 | ~1250 行 | ~1780 行(含 connection) |
| 重协商 | SDK 内部 | SDK 内部 | renegotiate() 手动处理 |
| 适用场景 | 生产环境 | 生产环境 | 开发/嵌入式/自托管 |
6.7 帧流向总结
输入方向(用户 → 管道)
用户音频/视频 (WebRTC)
│
▼
[Transport Client]
│ read_next_audio_frame() / 音频回调
▼
[InputTransport.push_audio_frame()]
│
▼
[_audio_in_queue] ← asyncio.Queue 桥接
│
▼
[_audio_task_handler]
├── 音频过滤 (BaseAudioFilter)
├── VAD 分析 (遗留路径)
└── push_frame(InputAudioRawFrame) ← audio_in_passthrough
│
▼
管道下游 (STT → UserTurnProcessor → LLM → ...)
输出方向(管道 → 用户)
管道上游 (... → TTS → OutputTransport)
│
▼
[OutputTransport.process_frame()]
│
├── TTSAudioRawFrame → MediaSender.audio_queue
├── OutputImageRawFrame → MediaSender.video_queue
├── OutputTransportMessageFrame → client.send_message()
└── InterruptionFrame → 清空 MediaSender 队列
│
▼
[MediaSender._audio_task_handler]
├── 分块 (40ms per chunk)
├── 重采样
├── 混音 (BaseAudioMixer)
├── Bot Speaking 状态检测
└── write_audio_frame(chunk)
│
▼
[Transport Client]
│ client.write_audio_frame() / audio_source.capture_frame()
▼
WebRTC → 用户
6.8 连接帧时间线
Pipeline Start
│
├── StartFrame ──→ InputTransport.start()
│ │
│ ├── client.join()/connect()
│ │ │
│ │ └── BotConnectedFrame ← bot 加入房间
│ │
│ └── set_transport_ready()
│ │
│ └── 创建音频任务,开始接收
│
├── StartFrame ──→ OutputTransport.start()
│ │
│ └── set_transport_ready()
│ │
│ └── 创建 MediaSender,准备发送
│
... 等待参与者 ...
│
├── on_participant_joined ──→ ClientConnectedFrame ← 用户加入
│
... 对话进行 ...
│
├── EndFrame ──→ InputTransport.stop()
│ │
│ ├── 取消音频任务
│ └── client.leave()/disconnect()
│
└── EndFrame ──→ OutputTransport.stop()
│
├── 发送剩余静音 (end_silence_secs)
├── 停止 MediaSender
└── client.leave()/disconnect()
七、Context Management & LLM Inference:代码到底想解决什么问题?
这一部分不再按“功能说明书”的方式写,而只回答三个问题:
- 这段代码要解决什么问题?
- 为什么作者要把它拆成现在这个样子?
- 什么时候系统才真的会向 LLM 服务发请求?
7.1 先看根问题:语音对话里的“用户输入”不是一个瞬时事件
在普通聊天应用里,用户按下回车,程序就知道:“现在可以把消息发给 LLM 了。”
但在 Pipecat 里,输入来自连续音频流。系统面对的不是一个清晰的 send() 时刻,而是一堆模糊信号:
- 一段段
InputAudioRawFrame - 逐步更新的
InterimTranscriptionFrame - 最终的
TranscriptionFrame - VAD 说“可能开始了”“可能结束了”
- turn strategy 说“现在真的可以算一轮结束了”
这套代码想解决的核心问题是:
在连续流输入里,如何找到一个足够可靠的时刻,把“用户刚才那一轮想表达的内容”固化下来,然后再把它发给 LLM?
如果没有这层设计,会立刻出现几个问题:
- 发得太早:用户还没说完,LLM 就开始回答,bot 抢话
- 发得太晚:用户已经说完,系统还在等,交互延迟大
- 边说边发:上下文里塞进一堆半句、废词、修正片段,LLM 上下文质量很差
- 工具调用后上下文混乱:函数结果还没回写到上下文,就又跑下一轮推理
所以,Pipecat 不把“收到一段文字”当成“可以请求 LLM”的条件,而是额外引入了一个中间层:Context Management。
7.2 LLMContext 这段代码想解决什么问题?
Source: src/pipecat/processors/aggregators/llm_context.py
如果直接让每个 LLM 服务自己维护聊天历史,会有两个问题:
- 每家模型厂商的消息格式不一样
- 管道里很多处理器都要读写上下文,如果每个处理器都绑定某一家 LLM,会导致整条 pipeline 被 provider 污染
所以这里引入了 LLMContext。
它的意图不是“再包一层数据结构”,而是:
把“当前对话状态”从具体 LLM 厂商协议里剥离出来,变成一个在 pipeline 内部通用的上下文对象。
先看最小定义:
# llm_context.py
class LLMContext:
def __init__(
self,
messages: Optional[List[LLMContextMessage]] = None,
tools: ToolsSchema | NotGiven = NOT_GIVEN,
tool_choice: LLMContextToolChoice | NotGiven = NOT_GIVEN,
):
self._messages = messages if messages else []
self._tools = LLMContext._normalize_and_validate_tools(tools)
self._tool_choice = tool_choice
从这个构造函数就能看出来,作者要保存的不是“聊天文本”,而是一次推理所需的完整输入状态:messages + tools + tool_choice。
这段代码实际上在解决三个具体问题:
问题 1:不同 LLM 提供商的上下文格式不同
LLMContext 提供一个“通用消息格式”,真正发给 OpenAI / Anthropic / Google / AWS 时,再由 adapter 做即时转换。
作者的意图很明确:
- pipeline 内部只操作一种上下文抽象
- provider 差异推迟到最后一刻处理
- 这样 aggregator、tool、memory、summary 都不需要绑死某个 provider
问题 2:上下文不只是文本,还可能包含图片、音频、工具定义
从 create_image_message()、create_audio_message() 可以看出来,这个类不是只为“聊天历史字符串数组”准备的。
例如图片消息会被转换成统一的上下文 message:
# llm_context.py
@staticmethod
def create_image_url_message(*, role: str = "user", url: str, text: Optional[str] = None):
content = []
if text:
content.append({"type": "text", "text": text})
content.append({"type": "image_url", "image_url": {"url": url}})
return {"role": role, "content": content}
作者真正想表达的是:
在 Pipecat 里,上下文不是 transcript log,而是“下一次推理所需的完整输入状态”。
所以它同时容纳:
- messages
- tools
- tool choice
- image content
- audio content
- provider-specific message
问题 3:上下文需要被多个处理器共同维护
LLMContext 被设计成一个可变对象,原因不是偷懒,而是 pipeline 里多个处理器都要协同更新它:
- user aggregator 追加 user message
- assistant aggregator 追加 assistant message
- function call 处理器回填 tool result
- summarizer 压缩旧上下文
- image 处理器追加 multimodal message
也就是说,LLMContext 本质上是:
一份由多种处理器共同编辑的“待推理状态”。
7.3 LLMContextAggregator 这段代码想解决什么问题?
Source: src/pipecat/processors/aggregators/llm_response_universal.py
看到 aggregator 这一层时,很容易误解成:“它只是把文本拼接一下。”
这不准确。
它真正解决的问题是:
原始输入事件太细碎、太不稳定,不能直接进入 LLM;必须先聚合成“可提交的上下文更新”。
也就是说,aggregator 不是字符串拼接器,而是 commit boundary。
7.3.1 LLMUserAggregator 的意图
LLMUserAggregator 想解决的是:
用户的一轮发言,应该在什么时候被认为是“完成的输入”?
代码里可以看出几个关键决定:
TranscriptionFrame到来时,只是先放进_aggregation- 并不会因为收到一段最终转录,就立即推送给 LLM
- 真正的提交发生在
_maybe_emit_user_turn_stopped()→push_aggregation()
先看“只积累、不提交”的代码:
# llm_response_universal.py
async def _handle_transcription(self, frame: TranscriptionFrame):
text = frame.text
if not text.strip():
return
self._aggregation.append(
TextPartForConcatenation(
text, includes_inter_part_spaces=frame.includes_inter_frame_spaces
)
)
关键代码:
# llm_response_universal.py
async def push_aggregation(self) -> str:
if len(self._aggregation) == 0:
return ""
aggregation = self.aggregation_string()
await self.reset()
self._context.add_message({"role": self.role, "content": aggregation})
await self.push_context_frame()
return aggregation
这里的设计意图很明确:
_aggregation是临时缓冲区LLMContext是正式状态push_context_frame()是“提交完成,可以交给 LLM 了”的信号
这等于把“听用户说话”与“提交一次可推理的输入”明确分开。
7.3.2 为什么 TranscriptionFrame 不能直接触发 LLM?
因为转录只是“看到了文本”,但系统还不知道:
- 用户是不是还在继续说
- 这是不是中间修正
- 是否要等待更完整的 turn stop 信号
- mute / interruption / external turn control 是否改变了时机
作者不信任单一信号,而是把最终决策交给:
- VAD
- turn strategies
- user turn controller
- aggregator commit
而 user turn stop 触发后的真正提交点是这里:
# llm_response_universal.py
async def _maybe_emit_user_turn_stopped(self, strategy=None, on_session_end: bool = False):
aggregation = await self.push_aggregation()
if not on_session_end or aggregation:
message = UserTurnStoppedMessage(
content=aggregation, timestamp=self._user_turn_start_timestamp
)
await self._call_event_handler("on_user_turn_stopped", strategy, message)
self._user_turn_start_timestamp = ""
这是一种典型的“多信号确认后再提交”的设计。
7.3.3 LLMAssistantAggregator 的意图
LLMAssistantAggregator 解决的是另一个问题:
assistant 的输出不是一次性字符串返回,而可能是流式文本、thought、tool call、tool result、image result 的混合过程,哪些东西应该回写上下文?回写之后是否应该重新推理?
所以 assistant aggregator 做了三件重要的事:
- 收集 assistant 文本,并在一轮回答结束后再写入上下文
- 在 function call 生命周期里,把 tool 调用和结果补写到上下文
- 决定某次工具结果回来后,是否应该重新触发 LLM
例如 function call 结果回写后,代码会显式判断要不要再跑一轮 LLM:
# llm_response_universal.py
if frame.result:
if properties and properties.run_llm is not None:
run_llm = properties.run_llm
elif frame.run_llm is not None:
run_llm = frame.run_llm
else:
run_llm = not bool(self._function_calls_in_progress)
if run_llm:
await self.push_context_frame(FrameDirection.UPSTREAM)
也就是说,assistant aggregator 不只是“记录 bot 说过的话”,它更像:
负责把一次 LLM 执行过程中产生的副作用,整理回上下文,使下一次推理看到的是完整状态。
7.4 这套代码为什么要把“上下文变化”和“LLM 请求”分开?
这是这一套设计里最重要的意图。
如果“只要上下文变了就立刻请求 LLM”,会产生很多错误时机:
- 用户话说到一半时就触发
- tool result 只回了一部分时就触发
- image 还没附着到上下文就触发
- summary 还没替换旧消息就触发
所以 Pipecat 明确分成两步:
- 更新
LLMContext - 显式发出
LLMContextFrame
对应到代码就是:
# llm_response_universal.py
self._context.add_message({"role": self.role, "content": aggregation})
await self.push_context_frame()
这里的 LLMContextFrame 不是普通数据包,它表达的是:
“当前上下文已经整理到一个可推理状态,现在可以交给 LLM 服务。”
这相当于数据库世界里的:
- 改内存对象 = edit
- 发
LLMContextFrame= commit + dispatch
这就是为什么 LLMContext 和 LLMContextFrame 被故意设计成两个概念,而不是一个。
7.5 那么,系统到底什么时候才会向 LLM 服务发请求?
答案非常具体:
不是在 context 被修改时,而是在 LLM service 收到
LLMContextFrame时。
这条边界在 src/pipecat/services/openai/base_llm.py 里非常清楚:
async def process_frame(self, frame: Frame, direction: FrameDirection):
...
if isinstance(frame, OpenAILLMContextFrame):
context = frame.context
elif isinstance(frame, LLMContextFrame):
context = frame.context
...
if context:
try:
await self.push_frame(LLMFullResponseStartFrame())
await self.start_processing_metrics()
await self._process_context(context)
finally:
await self.stop_processing_metrics()
await self.push_frame(LLMFullResponseEndFrame())
这段代码背后的意图非常直接:
- LLM service 不负责判断“现在该不该跑”
- 它只负责:“如果有人给了我一个
LLMContextFrame,我就执行推理”
真正执行 provider 请求的是 _process_context(context)。以 OpenAI 风格实现为例:
# openai/base_llm.py
@traced_llm
async def _process_context(self, context: OpenAILLMContext | LLMContext):
await self.start_ttfb_metrics()
chunk_stream = await (
self._stream_chat_completions_specific_context(context)
if isinstance(context, OpenAILLMContext)
else self._stream_chat_completions_universal_context(context)
)
async with _closing(chunk_stream) as chunk_iter:
async for chunk in chunk_iter:
...
所以 “是否请求 LLM” 的决策权在上游 aggregator / controller 手里,不在 provider 实现手里。
这是一种很强的职责隔离:
- 上游决定时机
- 下游决定如何调用模型
7.6 从代码看,哪些事件会真正触发一次 LLM 请求?
从 llm_response_universal.py 和 base_llm.py 看,真正会走到 LLMContextFrame -> _process_context() 这条路径的情况主要有这些:
情况 1:用户一轮发言结束
这是最常见的一种。
流程是:
TranscriptionFrame持续累积到_aggregation- turn controller 判定用户轮次结束
_maybe_emit_user_turn_stopped()调用push_aggregation()- user message 被写入
LLMContext push_context_frame()发出LLMContextFrame- LLM service 收到该 frame,开始请求模型
也就是说:
对 Pipecat 而言,“用户说完了”才是一次标准 LLM 请求的触发条件,而不是“识别出了一句文字”。
情况 2:代码显式发送 LLMRunFrame
LLMRunFrame 的含义是:
不管用户 turn 逻辑,现在就用当前 context 跑一次 LLM。
对应代码非常短,说明它本质上就是一个“立即提交当前上下文”的快捷入口:
# llm_response_universal.py
async def _handle_llm_run(self, frame: LLMRunFrame):
await self.push_context_frame()
这通常用于:
- 初始化 prompt 后立即开场
- function/tool 逻辑里手动 re-run
- 非语音场景下显式驱动
情况 3:追加 / 更新 messages 且 run_llm=True
比如:
LLMMessagesAppendFrameLLMMessagesUpdateFrame
它们先修改上下文,然后在 run_llm=True 时主动发出 LLMContextFrame。
# llm_response_universal.py
async def _handle_llm_messages_append(self, frame: LLMMessagesAppendFrame):
self.add_messages(frame.messages)
if frame.run_llm:
await self.push_context_frame()
作者的意图是提供一种“程序驱动”的入口,让外部逻辑不用伪造用户说话流程,也能安全触发推理。
情况 4:function call 结果回写后需要继续推理
tool 调用完成时,assistant aggregator 会把结果补写回 context。
然后它再判断要不要 re-run:
- 如果
properties.run_llm明确指定,就按这个值 - 否则看
frame.run_llm - 再否则,如果这是最后一个 in-progress function call,就默认继续跑
这段代码想解决的问题是:
当 LLM 调用工具后,下一轮推理必须看到完整工具结果,否则 agent 状态是不闭环的。
情况 5:图片或其他多模态内容被追加进 context
如果用户图片被成功加进 LLMContext,assistant aggregator 也可能立即重新推理。
这说明作者的思路是统一的:
只要上下文发生了“足以改变推理结果”的正式提交,就可以选择再发一轮
LLMContextFrame。
7.7 哪些情况不会触发 LLM 请求?
这点同样重要,因为它说明作者在刻意避免什么。
不会触发 1:只收到 TranscriptionFrame
因为这只是候选输入,还没经过 turn completion 确认。
不会触发 2:只是改了 LLMContext,但没有发 LLMContextFrame
上下文变化本身不是执行信号。
这正是为什么 “写上下文” 和 “发 frame” 是分开的两行代码,而不是一个封装动作。
不会触发 3:只改了 tools / tool choice
这会更新后续推理所需的配置,但标准文本 LLM 不会仅因为工具配置改变就自动起新请求。
不会触发 4:工具调用刚开始,还没拿到结果
因为这时上下文还不完整。
不会触发 5:上下文被 gate 住
GatedLLMContextAggregator 的存在说明作者明确预留了“上下文已准备好,但暂时还不能放行”的场景。
相关代码很直接:
# gated_llm_context.py
elif isinstance(frame, (LLMContextFrame, OpenAILLMContextFrame)):
if self._start_open:
self._start_open = False
await self.push_frame(frame, direction)
else:
self._last_context_frame = frame
这表明 Pipecat 在架构上承认一件事:
“可推理” 和 “现在允许推理” 不是同一件事。
7.8 从设计意图看,这套代码最想保护的是什么?
如果把这一整套 Context Management + LLM Inference 代码抽象成一句话,它最想保护的是:
不要在错误的时机,把不完整的状态发给模型。
所有这些类都在围绕这件事工作:
LLMContext:保存正式状态LLMUserAggregator:把零碎输入整理成一轮用户消息LLMAssistantAggregator:把输出、工具、图片、summary 整理回状态LLMContextFrame:声明“状态已经准备好”LLMService:只在收到这个声明时才执行推理
所以它背后的设计哲学不是“快速把文本发出去”,而是:
先把状态整理正确,再请求模型。
在 voice AI / multimodal agent 里,这比“看到文本就立刻推理”要重要得多。
7.9 一个最短的正确心智模型
如果你以后再读这部分代码,只要记住下面这四句话就够了:
LLMContext是状态- aggregator 是提交者
LLMContextFrame是执行信号- LLM service 是执行者
再换成一句更工程化的话:
Pipecat 把“整理状态”和“调用模型”分成了两个阶段,中间用 frame 明确隔开。
这就是这段代码真正想解决的问题,也是它存在的主要意图。
7.10 LLM Inference:这段代码为什么不直接返回一个完整字符串?
如果只看产品表面,LLM service 似乎只需要做一件事:
把
LLMContext发给模型,然后拿回一段回答。
但 Pipecat 没有这样设计。它把 LLM 推理拆成了下面几类独立 frame:
LLMFullResponseStartFrameLLMTextFrameLLMFullResponseEndFrameFunctionCallsStartedFrameFunctionCallInProgressFrameFunctionCallResultFrame
这背后要解决的问题是:
LLM 的输出不是“一个最终字符串”,而是一个会影响下游行为的流式事件序列。
因为在 voice agent 里,下游并不想等整个 completion 完成后再处理:
- TTS 希望尽早拿到文本片段开始说话
- assistant aggregator 需要把输出逐步回写 context
- tool calling 需要在模型刚决定调用工具时就切换执行路径
- metrics / observer / RTVI 需要知道这一轮回复何时开始、何时结束
所以 Pipecat 的设计意图不是“返回结果”,而是:
把一次 LLM completion 展开成一个可以被 pipeline 继续消费的 frame 流。
7.10.1 一次普通 LLM 推理,关键 frame 是怎么发的?
在 OpenAI 风格实现里,真正的入口仍然是 process_frame():
async def process_frame(self, frame: Frame, direction: FrameDirection):
...
if isinstance(frame, OpenAILLMContextFrame):
context = frame.context
elif isinstance(frame, LLMContextFrame):
context = frame.context
...
if context:
try:
await self.push_frame(LLMFullResponseStartFrame())
await self.start_processing_metrics()
await self._process_context(context)
finally:
await self.stop_processing_metrics()
await self.push_frame(LLMFullResponseEndFrame())
这里作者想解决的是两个问题:
- 给下游一个明确的回复生命周期边界
- 把 provider 内部的流式实现包装成统一协议
于是对 pipeline 来说,一次 LLM 推理就不再是“某个 SDK 调用”,而是:
LLMContextFrame
-> LLMFullResponseStartFrame
-> 0..N 个 LLMTextFrame / function-call 相关 frame
-> LLMFullResponseEndFrame
这个抽象非常重要,因为下游 processor 根本不需要知道你用的是 OpenAI、Anthropic 还是 Google。
7.10.2 LLMTextFrame 真正解决的是什么问题?
LLMTextFrame 的定义非常简单:
class LLMTextFrame(TextFrame):
"""Text frame generated by LLM services."""
def __post_init__(self):
super().__post_init__()
self.includes_inter_frame_spaces = True
看起来只是一个普通文本 frame,但它解决的是:
让 LLM 输出可以按 token / chunk 流式进入后续处理器,而不是等待完整字符串。
OpenAI 风格实现里,文本 chunk 到达后会立即推下游:
if chunk.choices[0].delta.content:
await self._push_llm_text(chunk.choices[0].delta.content)
_push_llm_text() 进一步决定是直接发 LLMTextFrame,还是先经过 incomplete-turn 过滤:
async def _push_llm_text(self, text: str):
if self._filter_incomplete_user_turns:
await self._push_turn_text(text)
else:
await self.push_frame(LLMTextFrame(text))
所以 LLMTextFrame 背后的设计意图不是“把字符串包一下”,而是:
把 LLM 输出从 provider SDK 的私有流,转成 Pipecat pipeline 的公共语言。
这一步完成后:
- TTS 可以边收边播
- observer 可以实时记录 bot text
- assistant aggregator 可以持续聚合回复
- RTVI 可以把 bot 的文本事件同步给前端
7.11 Function Calling:为什么要拆成 Started / InProgress / Result 三段?
很多人第一次看这段代码会觉得奇怪:
为什么工具调用不直接“执行函数 -> 拿结果 -> 回写上下文”?
Pipecat 没这么做,而是故意拆成三类 frame:
FunctionCallsStartedFrameFunctionCallInProgressFrameFunctionCallResultFrame
因为作者真正想解决的问题不是“执行一个 Python 函数”,而是:
把“模型决定调用工具”这件事,变成 pipeline 中一个可观测、可中断、可回写上下文的状态机。
这对实时 agent 很关键。
7.11.1 FunctionCallsStartedFrame:先声明“接下来要进入工具阶段”
当 provider 输出里出现 tool call 后,OpenAI 风格实现不会立刻自己偷偷执行函数,而是先收集完整的函数名、参数、tool_call_id:
if function_name and arguments:
functions_list.append(function_name)
arguments_list.append(arguments)
tool_id_list.append(tool_call_id)
function_calls = []
for function_name, arguments, tool_id in zip(
functions_list, arguments_list, tool_id_list
):
arguments = json.loads(arguments)
function_calls.append(
FunctionCallFromLLM(
context=context,
tool_call_id=tool_id,
function_name=function_name,
arguments=arguments,
)
)
await self.run_function_calls(function_calls)
然后 run_function_calls() 做的第一件事不是运行 handler,而是先广播:
async def run_function_calls(self, function_calls: Sequence[FunctionCallFromLLM]):
...
await self._call_event_handler("on_function_calls_started", function_calls)
await self.broadcast_frame(FunctionCallsStartedFrame, function_calls=function_calls)
这一步的意图是:
让整个系统先知道:LLM 这一轮已经不再是纯文本输出,而是进入工具调用阶段。
assistant aggregator 收到这个 frame 后,会先把这些 tool_call_id 记成 “待完成”:
async def _handle_function_calls_started(self, frame: FunctionCallsStartedFrame):
for function_call in frame.function_calls:
self._function_calls_in_progress[function_call.tool_call_id] = None
也就是说,这个 frame 不是结果通知,而是一个状态初始化动作。
7.11.2 FunctionCallInProgressFrame:为什么工具刚开始就要写回 context?
真正开始执行某个 function 时,LLMService 会先广播 FunctionCallInProgressFrame:
await self.broadcast_frame(
FunctionCallInProgressFrame,
function_name=runner_item.function_name,
tool_call_id=runner_item.tool_call_id,
arguments=runner_item.arguments,
cancel_on_interruption=item.cancel_on_interruption,
)
frame 的定义也明确说明了它为什么是 UninterruptibleFrame:
class FunctionCallInProgressFrame(ControlFrame, UninterruptibleFrame):
"""Frame signaling that a function call is currently executing.
This is an uninterruptible frame because we always want to update the
context.
"""
这句话已经把设计意图说透了:
即使发生 interruption,也必须把“assistant 已经发起过这个 tool call”这件事写进上下文。
assistant aggregator 收到后,会立刻把两条消息写回 LLMContext:
self._context.add_message(
{
"role": "assistant",
"tool_calls": [
{
"id": frame.tool_call_id,
"function": {
"name": frame.function_name,
"arguments": json.dumps(frame.arguments, ensure_ascii=False),
},
"type": "function",
}
],
}
)
self._context.add_message(
{
"role": "tool",
"content": "IN_PROGRESS",
"tool_call_id": frame.tool_call_id,
}
)
这段代码真正想避免的是一种上下文断裂:
- 模型明明已经要求调用工具
- 工具也已经开始跑
- 但 conversation history 里却看不出这一步发生过
对某些 provider,尤其是 Anthropic 这种对 tool-use 对话结构要求严格的模型,这种断裂会直接破坏下一轮推理。
所以这里不是“为了记录日志”,而是:
先把工具调用本身作为 assistant 对话行为写进上下文,再去执行工具。
7.11.3 FunctionCallResultFrame:结果到达后,为什么还要决定要不要再跑一轮 LLM?
工具函数真正完成后,不是直接修改 context,而是通过回调再广播一个结果 frame:
async def function_call_result_callback(
result: Any, *, properties: Optional[FunctionCallResultProperties] = None
):
await self.broadcast_frame(
FunctionCallResultFrame,
function_name=runner_item.function_name,
tool_call_id=runner_item.tool_call_id,
arguments=runner_item.arguments,
result=result,
run_llm=runner_item.run_llm,
properties=properties,
)
assistant aggregator 再负责把结果正式回写到 context,并决定是否 re-run:
if frame.result:
if properties and properties.run_llm is not None:
run_llm = properties.run_llm
elif frame.run_llm is not None:
run_llm = frame.run_llm
else:
run_llm = not bool(self._function_calls_in_progress)
if run_llm:
await self.push_context_frame(FrameDirection.UPSTREAM)
这里解决的是一个 agent 框架里最常见但最容易写乱的问题:
工具结果什么时候算“足够完整”,可以重新交给 LLM 继续思考?
Pipecat 的答案是:
- 如果调用者明确指定
run_llm,就按显式配置 - 否则,如果还有别的 tool call 没完成,先不要 re-run
- 否则默认在最后一个结果到达后继续推理
这等价于一种很实用的工程策略:
先把同一轮 tool calls 收齐,再把完整结果集交回模型。
这样可以避免:
- 模型看到半套工具结果就开始下一轮推理
- 并行工具调用互相覆盖上下文
- assistant 上下文里出现 “tool 已开始但没有收尾” 的坏状态
7.12 这一整套 LLM Inference + Function Calling 代码最核心的意图
如果把这部分代码压缩成一句话,它真正想解决的是:
把一次 completion 从“黑盒 SDK 调用”拆成 pipeline 可以理解的事件流,并保证 tool call 的每个阶段都能被上下文正确记录。
所以你在读这部分代码时,最好的心智模型不是:
- LLM service 返回字符串
- tool handler 返回结果
而是:
LLMContextFrame触发一次推理LLMFullResponseStartFrame / EndFrame划出回复边界LLMTextFrame让文本可以流式进入下游FunctionCallsStartedFrame声明进入工具阶段FunctionCallInProgressFrame把工具调用动作先写进 contextFunctionCallResultFrame把工具结果补齐,并决定是否再跑一轮 LLM
这套拆分看起来比“直接写个 await llm.chat()”复杂很多,但它换来的能力是:
- 可流式
- 可观测
- 可中断
- 可多工具并行
- 可把工具过程纳入统一上下文
这就是 Pipecat 在 LLM inference 这层真正的工程目标。
八、LLM Inference in the Pipeline:大模型并不是终点,而是中间站
刚开始读 Pipecat 的代码时,我很容易带着一个来自传统应用层的直觉:大模型服务应该是系统的中心。用户输入来了,把历史消息交给 LLM,LLM 返回一段字符串,再交给 TTS 或前端去消费。这种理解不能说错,但它会让人误判 Pipecat 里最重要的设计选择。
在 Pipecat 里,LLM 当然很重要,但它并没有被写成一个“凌驾于 pipeline 之上的智能大脑”。它反而被老老实实地放回到了 pipeline 里,当成一个普通的 FrameProcessor。这一点看起来很朴素,实际上非常关键。因为一旦把 LLM 重新放回 pipeline,它就不再只是“生成文本的黑盒”,而是变成了一个既消费 frame、也生产 frame、同时还参与全局状态推进的中间节点。
理解这一点之后,很多看似复杂的实现 suddenly 变得顺理成章。LLMContextFrame 不再只是“消息列表”;它是一次正式推理的启动信号。LLMTextFrame 不再只是“token 文本”;它是下游语音和 UI 可以实时消费的事件。FunctionCallInProgressFrame 和 FunctionCallResultFrame 也不只是工具机制的附属品,而是 LLM 与整个 pipeline 之间进行协作时必须暴露出来的状态变化。
8.1 先把大模型放回 pipeline 里看
Pipecat 的 pipeline 本质上只是一个线性 processor 链。Pipeline 自己不理解音频、不理解文本、也不理解 LLM,它只负责把 frame 按方向送进处理器序列:
async def process_frame(self, frame: Frame, direction: FrameDirection):
await super().process_frame(frame, direction)
if direction == FrameDirection.DOWNSTREAM:
await self._source.queue_frame(frame, FrameDirection.DOWNSTREAM)
elif direction == FrameDirection.UPSTREAM:
await self._sink.queue_frame(frame, FrameDirection.UPSTREAM)
这段代码带来的后果是,LLM 在运行时没有任何“特殊通道”。它和别的 processor 一样,必须靠 frame 来接收输入,也必须靠 frame 来表达输出。换句话说,Pipecat 不允许你在 pipeline 的中间偷偷做一件只有自己知道的事。只要一次推理对系统其它部分有影响,它就必须显式地以 frame 的形式暴露出来。
这也是为什么我会说,Pipecat 里的 LLM 不是终点,而是中间站。上游负责把状态整理到“可以推理”的程度,下游负责消费推理过程中不断冒出来的中间结果,而 LLM service 只是把这两者连接起来。
8.2 LLM 真正收到的不是“用户文本”,而是一种提交后的状态
LLM 在 pipeline 里并不是直接监听麦克风,也不是直接监听 TranscriptionFrame。它真正关心的是:有没有人把一份正式的上下文提交给我。
这个入口在 provider 实现里写得很干净:
async def process_frame(self, frame: Frame, direction: FrameDirection):
await super().process_frame(frame, direction)
context = None
if isinstance(frame, OpenAILLMContextFrame):
context = frame.context
elif isinstance(frame, LLMContextFrame):
context = frame.context
else:
await self.push_frame(frame, direction)
if context:
try:
await self.push_frame(LLMFullResponseStartFrame())
await self.start_processing_metrics()
await self._process_context(context)
finally:
await self.stop_processing_metrics()
await self.push_frame(LLMFullResponseEndFrame())
这里最打动我的一点是:LLM service 完全不参与“时机判断”。它既不关心用户是不是刚说完一句话,也不关心工具结果是不是刚刚返回,更不关心这轮推理是语音触发的还是代码触发的。它只接受一种非常明确的信号:LLMContextFrame。
这其实是在给整个系统建立边界。上游 aggregator 和 controller 可以非常复杂,可以处理 VAD、turn detection、transcription aggregation、message append、tool result merge,但它们做的所有事最后都要落在一个动作上:把一份已经提交好的上下文发给 LLM service。 从那一刻开始,LLM service 才接管。
所以在 Pipecat 里,大模型并不直接面对原始输入,它面对的是经过 pipeline 其他部分整理过的状态快照。
8.3 一旦开始推理,LLM 就开始主动影响整条 pipeline
传统 SDK 风格的思路通常是:response = await llm.chat(messages)。但 Pipecat 故意不让 LLM 只返回一个对象。它要把推理过程拆开,让整条 pipeline 都能看到这次回复是如何展开的。
最明显的两个边界 frame 是:
LLMFullResponseStartFrameLLMFullResponseEndFrame
这两个 frame 看起来简单,作用却很大。它们意味着下游可以明确知道“bot 正在开始回复”和“bot 这轮回复已经结束”。对于 TTS、transport、observer、idle processor、RTVI 这类需要感知回复生命周期的组件,这种边界信息比最终文本本身还重要。因为它们关心的不是句子长什么样,而是系统当前处于什么阶段。
而在这两个边界中间,LLM service 不断发出的就是 LLMTextFrame。OpenAI 风格实现里,这一步几乎没有额外包装:
if chunk.choices[0].delta.content:
await self._push_llm_text(chunk.choices[0].delta.content)
继续往下看,_push_llm_text() 的逻辑也很克制:
async def _push_llm_text(self, text: str):
if self._filter_incomplete_user_turns:
await self._push_turn_text(text)
else:
await self.push_frame(LLMTextFrame(text))
这背后体现出来的是一种很鲜明的工程偏好:LLM 输出一旦可消费,就立刻放进 pipeline,而不是先在 service 内部攒成一个大字符串。
这让后面的处理器可以边收边工作。TTS 可以尽早合成音频,前端可以实时显示 bot text,assistant aggregator 可以持续聚合 assistant reply。也正因为 LLM 是以 frame 的方式参与 pipeline,这些事情都变成了很自然的下游消费,而不是某个 provider SDK 暴露给每个调用者的一堆回调函数。
8.4 LLM 在这里既像生产者,也像一个状态转换器
如果只是发 LLMTextFrame,LLM service 还只是一个文本生产者。但 Pipecat 里真正有意思的地方在于,LLM 还会在推理过程中改变系统接下来的执行路径。
最典型的例子就是 tool calling。
当模型的 streamed delta 里开始出现 tool_calls,OpenAI 风格实现并不会马上把它们当成最终结果返回,而是先把函数名、参数片段、tool call id 在本地拼起来:
if chunk.choices[0].delta.tool_calls:
tool_call = chunk.choices[0].delta.tool_calls[0]
if tool_call.index != func_idx:
functions_list.append(function_name)
arguments_list.append(arguments)
tool_id_list.append(tool_call_id)
function_name = ""
arguments = ""
tool_call_id = ""
func_idx += 1
if tool_call.function and tool_call.function.name:
function_name += tool_call.function.name
tool_call_id = tool_call.id
if tool_call.function and tool_call.function.arguments:
arguments += tool_call.function.arguments
当这一轮流式输出结束后,LLM service 才把它们组装成 FunctionCallFromLLM,然后进入 run_function_calls()。
到这里,LLM 的身份已经发生变化了。它不再只是一个“吐文本的节点”,而是在说:
这轮 pipeline 的后续行为,不应该继续沿着“文本 -> TTS”这条线走下去,而应该切换到“工具执行 -> 更新上下文 -> 可能再次推理”。
也就是说,LLM 在 Pipecat 里既是生成器,也是路由转换器。它通过产出不同类型的 frame,影响整个 pipeline 的后续路径。
8.5 为什么 function calling 一定要公开成 pipeline 事件
如果只从“把函数跑完”这个局部目标看,完全可以把工具调用藏在 LLM service 内部:service 收到 tool call,执行 Python handler,拿到结果,再继续请求模型。这样从单个模块视角看会很省事。
但 Pipecat 没有这样写,我认为这是对的。因为一旦把工具调用藏起来,pipeline 的其余部分就失明了。assistant aggregator 不知道上下文里该何时写入 tool call,observer 看不到工具延迟,transport 不知道当前系统是“还在说话”还是“已经转入工具执行”,上层也无法在 interruption、timeout 或并行工具场景里保持一致状态。
所以 LLMService.run_function_calls() 第一件事不是执行 handler,而是先广播:
await self.broadcast_frame(FunctionCallsStartedFrame, function_calls=function_calls)
而 FrameProcessor.broadcast_frame() 自己又很直接:
async def broadcast_frame(self, frame_cls: Type[Frame], **kwargs):
downstream_frame = frame_cls(**kwargs)
upstream_frame = frame_cls(**kwargs)
downstream_frame.broadcast_sibling_id = upstream_frame.id
upstream_frame.broadcast_sibling_id = downstream_frame.id
await self.push_frame(downstream_frame)
await self.push_frame(upstream_frame, FrameDirection.UPSTREAM)
这说明 tool calling 在 Pipecat 里从来不是一个“service 私有实现细节”。它是整条 pipeline 都有权感知的系统事件。下游能收到,上游也能收到。谁需要感知,就在自己的 processor 里处理相应 frame。这个设计很朴素,但可扩展性极强,因为它没有假定“只有某一个组件会关心工具调用”。
8.6 assistant aggregator 才是把 LLM 输出重新变成上下文的人
我觉得 Pipecat 的一个高明之处,在于它没有让 LLM service 顺手维护会话状态。很多框架都喜欢把“请求模型”和“更新上下文”揉在一起,这样短期看代码更少,长期却很难处理多模态输入、工具结果、summary 或 provider 差异。
Pipecat 把这件事拆开了。LLM service 只负责把模型输出表达为 frame;真正把这些输出重新沉淀进 LLMContext 的,是 assistant aggregator。
比如收到 FunctionCallInProgressFrame 时,assistant aggregator 会马上把 assistant 的 tool call 和一个 tool 角色的 IN_PROGRESS 消息写回上下文:
self._context.add_message(
{
"role": "assistant",
"tool_calls": [
{
"id": frame.tool_call_id,
"function": {
"name": frame.function_name,
"arguments": json.dumps(frame.arguments, ensure_ascii=False),
},
"type": "function",
}
],
}
)
self._context.add_message(
{
"role": "tool",
"content": "IN_PROGRESS",
"tool_call_id": frame.tool_call_id,
}
)
收到 FunctionCallResultFrame 后,再把 tool result 补齐,并决定是否重新推理:
if frame.result:
if properties and properties.run_llm is not None:
run_llm = properties.run_llm
elif frame.run_llm is not None:
run_llm = frame.run_llm
else:
run_llm = not bool(self._function_calls_in_progress)
if run_llm:
await self.push_context_frame(FrameDirection.UPSTREAM)
这让我越来越确定,Pipecat 对 LLM 的理解不是“它拥有会话”,而是“它参与会话的推进”。真正持续存在、可被再次提交、也可被其它 processor 修改的,是 LLMContext,而不是 provider SDK 的一次调用对象。
8.7 我理解中的核心交互:LLM 站在两种时间之间
读到这里,我对 Pipecat 里 LLM 的角色有了一个更清晰的感觉:它站在两种不同的时间之间。
一种是对话时间。用户说话、停顿、工具执行、bot 回复,这些事件在现实时间里发生,它们由 VAD、turn controller、aggregator、transport 等组件不断推进。
另一种是推理时间。一旦 LLMContextFrame 被提交,LLM service 就进入了一段相对封闭的计算过程:开始回复、流式吐字、也许产生 tool call、等待 tool result、再继续下一轮推理。
Pipecat 的聪明之处,不在于消灭这两种时间的差异,而在于用 frame 把它们对接起来。LLMContextFrame 把对话时间压缩成一次可推理的提交,LLMTextFrame 和 function call frames 又把推理时间重新展开回 pipeline,让其他 processor 能继续参与。
所以我现在更愿意把 LLM service 看成一个“时间转换器”:它接收的是已经整理好的会话状态,吐出来的是一串能继续推动系统前进的事件。
8.8 结尾:为什么这种写法比直接 await llm.chat() 更值得学
如果只是写一个 demo,直接 await llm.chat() 当然更快。但一旦你想做实时语音、打断、tool calling、前端同步显示、metrics、可观测性,单个异步函数返回值这套模型就开始变得捉襟见肘。因为系统需要的不是“一个最终答案”,而是“一次答案生成过程中的每个关键状态”。
Pipecat 在这部分代码里给出的答案非常统一:不要把 LLM 当成 pipeline 之外的神秘能力,而是把它变成 pipeline 中一个严格说清输入、输出、边界和副作用的 processor。
也正因为这样,LLM 才能真正和 transport、TTS、aggregator、observer、tool runner 这些组件站在同一个抽象层上协作。它不再是一个调用点,而是一段会被其他 processor 理解、观察、接续的 frame 流。
我觉得这就是这部分代码最值得学的地方。它不是在教你“如何接一个大模型 SDK”,而是在示范:当一个大模型进入实时系统之后,应该如何被放回工程结构里。
九、Function Calling:把模型的“行动意图”变成系统里的公共事件
如果只从产品视角看,Function Calling 很容易被理解成一个简单功能:模型决定调用某个工具,程序把这个工具跑一下,再把结果交还给模型。这种说法对用户足够,但对读源码的人帮助不大。因为在 Pipecat 里,Function Calling 真正棘手的部分从来不是“调用一个 Python 函数”,而是如何把模型的行动意图,可靠地纳入一条实时 pipeline。
这也是我读完相关实现后最强烈的感受。Pipecat 这套代码并不是在解决“怎么调用工具”这么狭窄的问题,它在解决的是一个更工程化的命题:当大模型在推理中途决定采取行动时,系统如何让这个行动变得可观测、可恢复、可中断、可重新进入上下文。
这听上去抽象,但源码的结构其实非常清晰。它把整个过程拆成三个层面:模型产生行动意图,LLM service 把意图转成 frame,assistant aggregator 把这些 frame 重新沉淀成正式上下文。正是这种拆分,让工具调用不再是 provider 内部的私有细节,而成为整个系统都能理解的一段公共状态变化。
9.1 模型提出的不是结果,而是一种“接下来该做什么”的请求
Pipecat 对 tool call 的第一个判断非常重要:模型并没有直接帮你完成任务,它只是提出了一个下一步执行计划。
在 OpenAI 风格实现里,这个计划不是一次性拿到的。模型的 streamed delta 会把函数名、参数和 tool call id 拆成很多碎片,service 需要先把它们拼起来:
if chunk.choices[0].delta.tool_calls:
tool_call = chunk.choices[0].delta.tool_calls[0]
if tool_call.index != func_idx:
functions_list.append(function_name)
arguments_list.append(arguments)
tool_id_list.append(tool_call_id)
function_name = ""
arguments = ""
tool_call_id = ""
func_idx += 1
if tool_call.function and tool_call.function.name:
function_name += tool_call.function.name
tool_call_id = tool_call.id
if tool_call.function and tool_call.function.arguments:
arguments += tool_call.function.arguments
这段代码看似只是 provider 解析逻辑,实际上已经透露出一个设计立场:tool call 在 Pipecat 里首先被视为推理过程中出现的结构化意图。因为它是流式到达的,系统不能天真地把第一个 token 当成完整命令,也不能在参数尚未拼完时就贸然执行工具。它必须先把“意图”收束成一个可以执行的对象。
当流式输出结束后,service 才会把这些信息组装成 FunctionCallFromLLM:
function_calls.append(
FunctionCallFromLLM(
context=context,
tool_call_id=tool_id,
function_name=function_name,
arguments=arguments,
)
)
我觉得这里最值得注意的是 context=context。Function call 并不是脱离会话的孤立动作,它始终绑定在一轮具体推理上下文上。也就是说,Pipecat 从一开始就把工具调用当作会话的一部分,而不是 callback 风格的旁路逻辑。
9.2 真正的分界线,不是“开始执行工具”,而是“让系统知道将要执行工具”
进入 run_function_calls() 后,最能体现设计品味的一点是:Pipecat 先广播事件,再运行函数。
async def run_function_calls(self, function_calls: Sequence[FunctionCallFromLLM]):
if len(function_calls) == 0:
return
await self._call_event_handler("on_function_calls_started", function_calls)
await self.broadcast_frame(FunctionCallsStartedFrame, function_calls=function_calls)
我认为这是整套实现里最关键的一个选择。很多框架会在这里直接进入 handler,尽快拿结果。但 Pipecat 偏偏先做了一件“看起来不产生业务结果”的事:向 pipeline 宣告,系统已经进入了 function-calling 阶段。
为什么这一步重要?因为工具调用从来不只是 LLM service 和 Python handler 之间的私事。只要系统里还有 assistant aggregator、metrics、observer、RTVI、idle processor、transport 控制这些组件,它们就都可能需要知道:现在的 bot 不再只是继续吐文本,而是在发起一个外部动作。
FunctionCallsStartedFrame 在这里起的作用,不是携带工具结果,而是建立一个公共前提:从现在开始,后续出现的某些状态变化,应当被解释为这轮工具调用生命周期的一部分。
这是一种很成熟的实时系统思路。先公开状态,再推进执行。这样一来,系统其他部分不需要依赖 provider 细节,也不需要猜测“是不是已经进入 tool call 了”,它们只要监听标准 frame 即可。
9.3 Handler 注册表解决的并不是查表问题,而是“行动能力的显式声明”
接下来 run_function_calls() 会把模型给出的 function name 映射到本地注册表:
if function_call.function_name in self._functions.keys():
item = self._functions[function_call.function_name]
elif None in self._functions.keys():
item = self._functions[None]
else:
logger.warning(
f"{self} is calling '{function_call.function_name}', but it's not registered."
)
continue
这当然是一个普通的查表过程,但我更愿意把它理解成“能力边界检查”。模型可以在语义空间里表达任何它认为合理的动作,但系统并不会因此自动拥有相应能力。Pipecat 要求开发者显式注册工具,这其实是在保护边界:llm的输出有时间并不可行,经常收到
这一点在 agent 框架里非常重要。因为一旦把模型输出直接当成可执行命令,工具系统就会从“能力扩展”滑向“能力失控”。Pipecat 用一个很简单的注册表,维持住了这条边界。
9.4 并行与串行不是性能选项,而是行为语义
LLMService 提供了 run_in_parallel 开关,看起来像一个普通性能参数,但读代码后会发现,它其实影响的是工具阶段的行为语义。
if self._run_in_parallel:
await self._run_parallel_function_calls(runner_items)
else:
await self._run_sequential_function_calls(runner_items)
并行模式下,每个 tool call 都会被放进独立 task:
for runner_item in runner_items:
task = self.create_task(self._run_function_call(runner_item))
tasks.append(task)
self._function_call_tasks[task] = runner_item
串行模式下,则被排进一个内部队列,由一个专门的 sequential runner 逐个执行。
这两种模式表面上只是“快一点”或“稳一点”的差别,实际上它们决定了系统如何理解同一轮多个 tool calls 的关系。并行意味着这些动作被视为可以独立推进的外部查询,串行则意味着它们应该被视为一个有顺序要求的执行脚本。
换句话说,Pipecat 在这里并没有把工具调度偷换成纯粹的 asyncio 实现细节,而是把它保留成框架层的显式语义。这一点很专业,因为它允许开发者依据业务模型而不是依据默认库行为,来定义 agent 的行动方式。
9.5 FunctionCallInProgressFrame 是整套设计里最有“状态机味道”的部分
在真正执行某个函数之前,Pipecat 会先广播一个 FunctionCallInProgressFrame:
await self.broadcast_frame(
FunctionCallInProgressFrame,
function_name=runner_item.function_name,
tool_call_id=runner_item.tool_call_id,
arguments=runner_item.arguments,
cancel_on_interruption=item.cancel_on_interruption,
)
我很喜欢这个设计,因为它说明框架作者真正关心的不是“函数有没有跑起来”,而是“系统状态是否已经切换到运行中”。这两件事听起来接近,但在实时 pipeline 里差别很大。前者只是某个 task 的局部状态,后者则是整个系统都需要知道的公共状态。
更值得注意的是,这个 frame 被定义成了 UninterruptibleFrame:
class FunctionCallInProgressFrame(ControlFrame, UninterruptibleFrame):
"""Frame signaling that a function call is currently executing.
This is an uninterruptible frame because we always want to update the
context.
"""
我认为这里的注释几乎已经把作者的意图说完了。工具调用一旦开始,哪怕后面发生打断,这个“已经开始”的事实也必须进入上下文。因为它不再是一次暂时性的实现细节,而是这段会话历史中真实发生过的一步动作。
在 assistant aggregator 这一侧,这个 frame 会被立即翻译成上下文里的两条消息:一条 assistant 的 tool call 记录,一条 tool 的 IN_PROGRESS 记录。
self._context.add_message(
{
"role": "assistant",
"tool_calls": [
{
"id": frame.tool_call_id,
"function": {
"name": frame.function_name,
"arguments": json.dumps(frame.arguments, ensure_ascii=False),
},
"type": "function",
}
],
}
)
self._context.add_message(
{
"role": "tool",
"content": "IN_PROGRESS",
"tool_call_id": frame.tool_call_id,
}
)
这一步非常关键。它意味着工具调用不是“等结果回来再补一条记录”,而是从开始那一刻起就进入了会话状态。只有这样,后续的取消、完成、重试、并行工具结果合并,才都有一个稳定的上下文落点。
9.6 超时与取消并不是异常分支,而是正常生命周期的一部分
要理解这个设计思想,最好的办法是把 _run_function_call 整个方法当成一个微型的并发系统来看。它内部同时管理着三条可能的退出路径,而所有路径最终都汇聚到同一个出口。
9.6.1 整体结构:handler 与 timeout 的竞态协调
_run_function_call(runner_item)
│
├── 1. broadcast FunctionCallInProgressFrame ← 向整个 pipeline 宣布"行动开始"
│
├── 2. 定义 function_call_result_callback() ← 统一的结果收口
│ └── nonlocal timeout_task ← 闭包捕获,用于互相取消
│
├── 3. 启动 timeout_task = create_task(timeout_handler())
│ └── sleep(effective_timeout) → callback(None)
│
├── 4. await asyncio.sleep(0) ← 确保 timeout 协程被 enter
│
├── 5. try: await handler(params) ← 正常执行路径
│ handler 内部调用 result_callback(result)
│ └── callback 内部取消 timeout_task
│
├── 6. except: push_error(fatal=False) ← 错误路径
│
└── 7. finally: cancel_task(timeout_task) ← 兜底清理
这里的设计要点在于:handler 和 timeout 是两个并发竞争的协程。谁先完成,谁就通过 function_call_result_callback 占据结果位,然后取消对方。
9.6.2 闭包互取消:nonlocal 的精妙用法
nonlocal timeout_task 让 callback 闭包可以访问外部的 timeout_task 引用。当 handler 正常完成并调用 callback 时,它做的第一件事不是广播结果,而是先取消 timeout。这保证了一个关键不变量:result callback 只会被调用一次。
反过来,如果 timeout 先到期,timeout_handler 调用 function_call_result_callback(None),这会广播一个 result=None 的 FunctionCallResultFrame。handler 此后即使完成也不会再触发第二次结果广播——因为要么 handler 被 cancel 了,要么 handler 执行完成但不再调用 callback。
9.6.3 await asyncio.sleep(0) ——看似多余实则关键
这一行 await asyncio.sleep(0) 是一个 asyncio 的经典技巧。create_task 只是把协程注册到事件循环,但协程本身还没有开始执行。如果 handler 同步地(在第一个 await 之前)就调用了 callback,而 callback 里取消 timeout_task,那么 timeout_handler 协程从未被进入过就被 cancel 了。
这在 Python 中会导致 RuntimeWarning: coroutine was never awaited。await asyncio.sleep(0) 强制让出一次控制权,给事件循环机会运行 timeout_handler 到第一个 await asyncio.sleep(effective_timeout) 处。这样即使后续立刻被 cancel,协程也已经被正式 enter 了,CancelledError 会在正确的 await 点被注入。
9.6.4 超时路径的收口
Pipecat 的 function runner 在调用 handler 时,会同时启动一个 timeout task:
async def timeout_handler():
try:
effective_timeout = (
item.timeout_secs
if item.timeout_secs is not None
else self._function_call_timeout_secs
)
await asyncio.sleep(effective_timeout)
await function_call_result_callback(None)
except asyncio.CancelledError:
raise
超时不是一个"框架外部的失败",而是继续纳入统一的 function-call 生命周期。result=None 在 assistant aggregator 侧不会触发 run_llm——因为 if frame.result: 中 None 是 falsy。这意味着超时的工具调用不会触发下一轮 LLM 推理。上下文中的 IN_PROGRESS 标记保持原样,但 _function_calls_in_progress 字典中的条目已被移除。
这是一个合理的设计——超时意味着"我们不知道结果",让 LLM 基于不完整信息继续推理是不安全的。
9.6.5 取消路径:从打断到上下文闭合的完整链路
取消路径的触发从用户打断开始,经过一条清晰的责任链:
用户开始说话
→ VAD / Turn Strategy 检测到打断
→ broadcast InterruptionFrame
→ LLMService._handle_interruptions()
→ for each registered function:
if entry.cancel_on_interruption:
→ _cancel_function_call(function_name)
→ cancel_task(task) # 取消正在执行的 handler
→ broadcast FunctionCallCancelFrame # 通知下游
→ AssistantAggregator._handle_function_call_cancel()
→ _update_function_call_result(..., "CANCELLED")
→ del _function_calls_in_progress[tool_call_id]
这里有三个重要的细节:
第一,cancel_on_interruption 是可配置的。 在 register_function() 时,开发者可以设置 cancel_on_interruption=False。某些关键操作(如数据库写入、支付确认)即使用户打断了,也不应该被取消。aggregator 在判断是否取消时会检查这个标志。
第二,取消后上下文被更新为 CANCELLED 而不是被删除。 _update_function_call_result 会找到之前写入的 IN_PROGRESS 记录并就地替换为 CANCELLED。这种策略保持了上下文消息列表的顺序稳定性。LLM 下次看到历史时,会知道"之前尝试调用过某个工具,但被取消了"——这是有价值的信息。
第三,_cancel_function_call 中的 remove_done_callback 防止了迭代时修改集合。 取消 task 会触发 _function_call_task_finished 回调删除字典项,造成运行时错误。所以取消前先移除回调,收集所有要取消的 task,循环结束后再统一清理。
9.6.6 错误路径:不致命的 push_error
except Exception as e:
await self.push_error(error_msg=error_message, exception=e, fatal=False)
finally:
if timeout_task and not timeout_task.done():
await self.cancel_task(timeout_task)
注意 fatal=False。一个工具调用的异常不应该杀死整个 pipeline。push_error 将 ErrorFrame 推向上游,应用层可以捕获并决定如何处理。finally 块兜底清理 timeout_task。
这里有一个微妙的问题:如果 handler 抛出异常,function_call_result_callback 不会被任何人调用。这意味着 _function_calls_in_progress 中的条目不会被移除。从 aggregator 的角度看,这个工具调用永远停留在 IN_PROGRESS 状态。
这可能是有意的设计——异常意味着"我们连’失败了’这个事实都无法安全地告诉上下文"。在这种极端情况下,保持 IN_PROGRESS 比写入错误的结果更安全。
9.6.7 三条路径的统一视角
| 退出路径 | 触发条件 | 结果值 | 上下文更新 | 触发下轮推理? |
|---|---|---|---|---|
| 正常完成 | handler 调用 callback(result) | 由 handler 决定 | IN_PROGRESS → result | 是(当所有 tool call 完成时) |
| 超时 | timeout_handler sleep 到期 | None | IN_PROGRESS 保持不变 | 否 |
| 取消 | InterruptionFrame 触发 | N/A(task 被 cancel) | IN_PROGRESS → CANCELLED | 否 |
| 异常 | handler 抛出 Exception | N/A(callback 未调用) | IN_PROGRESS 保持不变 | 否(stuck) |
这张表说明了 Pipecat 的核心设计理念:只有正常完成且所有工具结果就绪时,才会推动系统进入下一轮认知循环。所有其他路径都被设计为"安全停留"——系统不会基于不完整或不可靠的信息继续推理。
这种写法很像一个真正成熟的状态机。正常完成、超时完成、取消完成,都是"完成"的不同原因,而不是三个互不相干的分支。对于上下文一致性来说,这一点非常重要。
Pipecat 的 function runner 在调用 handler 时,会同时启动一个 timeout task:
async def timeout_handler():
try:
effective_timeout = (
item.timeout_secs
if item.timeout_secs is not None
else self._function_call_timeout_secs
)
await asyncio.sleep(effective_timeout)
logger.warning(
f"{self} Function call [{runner_item.function_name}:{runner_item.tool_call_id}] timed out after {effective_timeout} seconds."
)
await function_call_result_callback(None)
except asyncio.CancelledError:
raise
这个实现让我印象很深,因为它没有把超时视为一个“框架外部的失败”,而是把它继续纳入统一的 function-call 生命周期。超时不会让状态悬空,也不会让上下文失去收尾;它最后仍然会回到 function_call_result_callback(),然后发出一个 FunctionCallResultFrame。
同样,取消也不是直接把 task 杀掉就算结束。assistant aggregator 在收到 FunctionCallCancelFrame 时,仍然会把结果更新成 CANCELLED:
if function_call and function_call.cancel_on_interruption:
self._update_function_call_result(frame.function_name, frame.tool_call_id, "CANCELLED")
del self._function_calls_in_progress[frame.tool_call_id]
这种写法很像一个真正成熟的状态机。正常完成、超时完成、取消完成,都是“完成”的不同原因,而不是三个互不相干的分支。对于上下文一致性来说,这一点非常重要。
9.7 FunctionCallResultFrame 的价值不在“带回结果”,而在“决定下一轮推理何时发生”
从接口上看,FunctionCallResultFrame 只是一个带有 result 字段的数据 frame:
class FunctionCallResultFrame(DataFrame, UninterruptibleFrame):
function_name: str
tool_call_id: str
arguments: Any
result: Any
run_llm: Optional[bool] = None
properties: Optional[FunctionCallResultProperties] = None
但真正让它变重要的,是 assistant aggregator 收到结果后的这段逻辑:
if frame.result:
if properties and properties.run_llm is not None:
run_llm = properties.run_llm
elif frame.run_llm is not None:
run_llm = frame.run_llm
else:
run_llm = not bool(self._function_calls_in_progress)
if run_llm:
await self.push_context_frame(FrameDirection.UPSTREAM)
我认为这里体现的是 Pipecat 对 agent 循环最成熟的一点理解:工具结果真正有价值的地方,不是它已经被算出来,而是它终于可以把系统带回下一轮推理。
如果把 function calling 只看成“调用外部函数”,你会很容易忽略这个关键时刻。但在 agent 系统里,工具执行的意义从来不止于副作用。它真正要完成的是一次认知闭环:模型发起行动,系统执行行动,行动结果重新进入上下文,模型据此继续思考。
也正因为如此,Pipecat 不会在每个 result 到达时盲目 re-run LLM。它要么听从显式的 run_llm 配置,要么等所有 in-progress tool calls 都收齐后再继续。这种保守其实很专业,因为它在避免一种非常常见的坏状态:模型拿着半套工具结果就开始下一轮思考。
9.8 我对这套源码的整体判断
读完整套 Function Calling 实现后,我的判断是:Pipecat 并没有把工具调用当成一个“给大模型加几个插件”的功能点,而是把它当成 LLM 推理过程中的外部行动机制。这两种看法的差别很大。
如果只是插件思路,代码的重点会放在 schema、handler 和返回值格式上。Pipecat 当然也有这些,但它更重视的是:
- 行动意图如何从流式模型输出中被拼出来
- 行动开始如何被整个 pipeline 感知
- 行动执行中如何保持上下文连续性
- 行动失败、超时、取消后如何正确收尾
- 行动结果何时才足以触发下一轮推理
这说明它真正想打造的不是“可以调用工具的 LLM”,而是“可以在实时系统里稳定行动的 agent”。
我认为这就是这部分源码最值得认真读的地方。它没有停留在接口封装层,而是在非常实际地回答一个更难的问题:当模型开始行动时,整个系统应该如何跟着一起进入行动状态。
十、Pipeline Termination:干净地结束,比开始更考验架构
一个实时 pipeline 最容易被低估的部分,不是如何启动,而是如何结束。启动通常只有一个方向:把 StartFrame 送进去,让所有处理器进入工作状态。但终止不是单一动作,它至少要回答三件事。
第一,系统是要优雅地结束,还是要立刻中止。
第二,结束信号要以什么方式穿过整条 pipeline,才能让资源释放和状态收尾发生在正确的顺序上。
第三,如果用户不说话、bot 也没有真正继续工作,系统如何判断“这条 pipeline 其实已经空转了太久”,从而自动退出。
Pipecat 在这部分代码里的设计非常成熟。它没有把 shutdown 写成某个全局 close(),而是坚持把终止也建模成 frame 流。这样做的好处是,终止过程不再是框架外的突然刹车,而是 pipeline 内部可以被每个处理器理解的正式生命周期阶段。
10.1 终止不是一个按钮,而是一组不同语义的 frame
Pipecat 至少区分了三种终止相关语义:
EndFrame: 优雅关闭,允许处理器按顺序收尾CancelFrame: 立即取消,不再等待剩余队列自然排空StopFrame: 停止当前 pipeline,但保留处理器运行状态
其中最常用的两个是 EndFrame 和 CancelFrame。它们的定义本身就已经透露了作者的意图:
class EndFrame(ControlFrame, UninterruptibleFrame):
"""Frame indicating pipeline has ended and should shut down.
Indicates that a pipeline has ended and frame processors and pipelines
should be shut down.
"""
class CancelFrame(SystemFrame):
"""Frame indicating pipeline should stop immediately.
Indicates that a pipeline needs to stop right away without
processing remaining queued frames.
"""
这两个 frame 看起来只是“柔和结束”和“强制结束”的差别,但在 Pipecat 的 frame 调度模型里,它们实际上对应两种完全不同的传播策略。
EndFrame 是 ControlFrame。这意味着它会按正常顺序排队,前面已经进入队列的 frame 仍然有机会被处理。它被标记成 UninterruptibleFrame,说明即使 pipeline 中途收到 InterruptionFrame,这个终止信号也不能丢。
CancelFrame 则是 SystemFrame。它天然拥有更高优先级,会被处理器优先取出处理。它表达的不是“等我收尾完再停”,而是“马上进入取消路径”。
Pipecat 在这里的架构判断非常清楚:终止不是一个布尔值,而是一种传播语义。
10.2 PipelineTask 是把“终止意图”翻译成“终止机制”的地方
真正把这些 frame 送进 pipeline 的,不是某个处理器自己,而是 PipelineTask。我一直觉得这是 Pipecat 很对的一层边界设计。用户代码、工具逻辑、observer、transport 甚至 pipeline 内部的 processor,都可以表达“我想结束这条任务”,但真正决定如何结束的,是 task 这一层。
这个转换发生在 _source_push_frame():
if isinstance(frame, EndTaskFrame):
await self.queue_frame(EndFrame(reason=frame.reason))
elif isinstance(frame, CancelTaskFrame):
await self.queue_frame(CancelFrame(reason=frame.reason))
elif isinstance(frame, StopTaskFrame):
await self.queue_frame(StopFrame())
这段代码很值得反复看。它说明 Pipecat 把“请求结束任务”和“真正结束 pipeline”故意拆成了两层:
EndTaskFrame/CancelTaskFrame/StopTaskFrame是意图EndFrame/CancelFrame/StopFrame是机制
这个分层带来两个重要好处。
第一,任何上游组件都可以安全地表达终止意图,而不必自己决定该用哪条底层传播路径。
第二,PipelineTask 作为生命周期管理者,可以统一处理等待结束、触发事件、做最终 cleanup 这些 task 级动作。
从工程角度看,这种设计比“在任意地方直接 close 资源”高级很多,因为它保住了 shutdown 的一致性。
10.3 优雅结束:为什么 EndFrame 必须真的走完整条 pipeline
PipelineTask._process_push_queue() 里有一段非常关键的主循环:
while running:
frame = await self._push_queue.get()
await self._pipeline.queue_frame(frame)
if isinstance(frame, (CancelFrame, EndFrame, StopFrame)):
await self._wait_for_pipeline_end(frame)
running = not isinstance(frame, (CancelFrame, EndFrame, StopFrame))
cleanup_pipeline = not isinstance(frame, StopFrame)
这里最重要的一句其实是 await self._wait_for_pipeline_end(frame)。这代表 PipelineTask 并不是“把 EndFrame 扔进去就算结束”,而是会一直等到该终止 frame 真正走到 pipeline 的 sink,才认为终止完成。
这一步之所以重要,是因为优雅结束的核心不是“发送一个结束命令”,而是“确保所有处理器都已经看见这个结束命令,并执行了自己的收尾逻辑”。
比如 transport 可能需要:
- 停止接收音频
- 发送剩余静音
- 刷掉输出缓冲
- 关闭线程或连接
而 aggregator、consumer、audio buffer 这类处理器也可能需要把手头聚合中的内容 flush 掉。只有让 EndFrame 真正经过它们,框架才能合理相信这些事情已经发生。
所以 EndFrame 的语义不是“从现在起不许再处理”,而是“从现在起进入有序退出流程”。
10.4 立即取消:为什么 CancelFrame 被做成高优先级 SystemFrame
相比之下,CancelFrame 代表的就是另一条路:不要再等,立即进入中止。
在 FrameProcessor 的优先队列里,SystemFrame 会被优先处理。这意味着取消一旦进入 pipeline,处理器会尽快感知到它,而不是等当前所有普通 frame 慢慢排到前面。
这种设计在高延迟或外部资源阻塞的场景里非常必要。比如:
- 网络服务挂死,继续等只会让 shutdown 拖更久
- 用户主动挂断,剩余输出已没有意义
- fatal error 已经发生,不值得再维持当前执行上下文
PipelineTask 自己也会在 fatal error 时主动转入取消路径:
elif isinstance(frame, ErrorFrame):
await self._call_event_handler("on_pipeline_error", frame)
if frame.fatal:
logger.error(f"A fatal error occurred: {frame}")
await self.queue_frame(CancelFrame())
这说明在 Pipecat 的设计里,CancelFrame 不只是“用户点了取消”,它还是框架层面对“继续有序收尾已经没有意义”的正式判断。
10.5 ParallelPipeline 为什么要专门同步 EndFrame 和 CancelFrame
这部分是很多人第一次读源码时容易忽略的细节,但它其实非常说明问题。ParallelPipeline 明确把 StartFrame、EndFrame、CancelFrame 当作需要跨分支同步的生命周期帧:
if isinstance(frame, (StartFrame, EndFrame, CancelFrame)):
self._frame_counter[frame.id] = len(self._pipelines)
self._synchronizing = True
await self.pause_processing_system_frames()
await self.pause_processing_frames()
对应的注释写得很直白:
- 如果
EndFrame从快分支先逃出去,下游可能开始关停,但慢分支还有内容没 flush 完 - 如果
CancelFrame从快分支先逃出去,PipelineTask可能会过早以为取消已经完成
这其实说明了一件很重要的事:终止的正确性不仅取决于单个处理器,也取决于整个 pipeline 拓扑。
在串行链路里,让终止 frame 往前走就够了;在并行链路里,还要保证所有分支对这个终止达成一致。否则,所谓 clean shutdown 就只是部分 clean。
10.6 Idle Detection:框架如何判断一条 pipeline 已经“没有真正活着”
除了显式结束,Pipecat 还支持自动 idle detection。这里的 idle 不是“没有任何 frame”,而是“在足够长时间里,没有出现被认为代表真实活跃度的关键 frame”。
PipelineTask 初始化时可以配置:
idle_timeout_secsidle_timeout_framescancel_on_idle_timeout
默认用于判断活跃度的 frame 是:
BotSpeakingFrameUserSpeakingFrame
这是一个非常合理的默认值。因为 heartbeat、metrics 这类 frame 即使持续在流动,也不能说明一段对话真的还在进行。Pipecat 要检测的是“有意义的 bot 交互是否还在发生”。
idle monitor 的主循环很简单:
async def _idle_monitor_handler(self):
running = True
while running:
try:
await asyncio.wait_for(self._idle_event.wait(), timeout=self._idle_timeout_secs)
self._idle_event.clear()
except asyncio.TimeoutError:
running = await self._idle_timeout_detected()
而真正触发事件的是 IdleFrameObserver:
async def on_push_frame(self, data: FramePushed):
if isinstance(data.frame, StartFrame) or isinstance(data.frame, self._idle_timeout_frames):
self._idle_event.set()
这套实现给我的感觉是很克制。它没有在每个处理器里塞进“我还活着”的心跳逻辑,而是只定义一个很小的“活跃度证据集合”,由 observer 在 task 边界统一收集。这样一来,idle detection 不会污染业务处理器,同时也不会把框架噪音误判成真实活动。
10.7 Idle 超时之后,为什么默认选择取消而不是优雅结束
idle 超时触发后的逻辑也很直接:
async def _idle_timeout_detected(self) -> bool:
if self._cancelled:
return False
logger.warning("Idle timeout detected.")
await self._call_event_handler("on_idle_timeout")
if self._cancel_on_idle_timeout:
logger.warning(f"Idle pipeline detected, cancelling pipeline task...")
await self.cancel()
return False
return True
这里默认是 cancel(),也就是进入 CancelFrame 路径,而不是 EndFrame 路径。我认为这个选择很有现实感。因为 idle timeout 通常意味着:
- 这条任务已经没有继续等待的价值
- 也没有明确的“最后一批业务数据”必须 flush
- 继续维持资源只会制造 hanging task
所以从资源管理角度看,idle timeout 更接近“回收僵尸任务”,而不是“礼貌结束一场仍在正常进行的会话”。这就是为什么默认路径是 cancel,而不是 graceful end。
当然,如果业务真的希望 idle 后执行某种更温和的退出策略,也可以在 on_idle_timeout 事件里自定义行为,并把 cancel_on_idle_timeout 设为 False。
10.8 Conditional Termination:最好的做法是发 frame,而不是在处理器里直接收摊
用户常见需求是:当某个条件满足时结束对话。这个条件可能来自:
- function call 的结果
- LLM 的结构化判断
- 用户明确说出“结束会话”
- 外部系统状态变化
Pipecat 在这类场景下最推荐的思路,不是“在某个 handler 里直接关 transport”,而是让条件逻辑发出 task-level 终止意图。
例如,一个 function call 完成后,如果你决定会话应当结束,更干净的做法是推一个 EndTaskFrame 或 CancelTaskFrame,让 PipelineTask 去翻译成真正的终止机制。
源码已经说明了为什么这么做是对的:
if isinstance(frame, EndTaskFrame):
await self.queue_frame(EndFrame(reason=frame.reason))
elif isinstance(frame, CancelTaskFrame):
await self.queue_frame(CancelFrame(reason=frame.reason))
这样做的好处是:
- 终止动作会沿着 pipeline 正式传播
- 所有处理器都能按框架约定收尾
- observer / runner / task 事件系统都能看到一致的生命周期结果
- 并行 pipeline、idle monitor、fatal error 这些已有机制不会被绕开
也就是说,条件式终止最稳妥的方式,不是跳出框架,而是借框架已有的生命周期通道来结束。
10.9 Runner 层的最后一道保障
再往外看一层,PipelineRunner 还会负责处理 SIGINT / SIGTERM,并把这些外部中断转换成 task 级取消:
async def _cancel(self):
await asyncio.gather(*[t.cancel() for t in self._tasks.values()])
run() 里的注释写得也很明确:PipelineTask 会负责处理 asyncio.CancelledError,确保 pipeline 有机会做正确的 shutdown。
这等于给终止链路补上了最后一道保护:即使结束不是由 pipeline 内部条件触发,而是来自操作系统信号,Pipecat 依然尽量把它收束到统一的 task cancellation 路径上。
10.10 一个实用的心智模型
读完这部分源码后,我会用下面这个模型来理解 Pipecat 的终止机制:
EndTaskFrame/CancelTaskFrame:有人提出“我想结束”PipelineTask:把这个意图翻译成正式终止 frameEndFrame:让整条 pipeline 按顺序完成收尾CancelFrame:让整条 pipeline 尽快进入中止IdleFrameObserver + idle monitor:负责发现“这条任务其实已经空转太久”PipelineRunner:把外部系统信号收束到相同的 task 生命周期里
如果用一句话总结这部分代码真正想解决的问题,那就是:
终止必须像启动一样,被当作框架级的一等事件来处理。
只有这样,clean shutdown 才不是一句口号,而是真正能在 transport、aggregator、LLM、parallel branches 和 task 管理之间稳定成立的工程事实。